
Big Data for E-commerce.
The year 2020 was full of challenges in many areas, and in many companies and organizations. Often, it was necessary to introduce radical changes or…
Read moreToday's fast-paced business environment requires companies to migrate their data infrastructure from on-premises centers to the cloud for better efficiency, scalability, and innovative service offerings. Moving a data platform from local systems to the cloud presents new development opportunities and cost-effectiveness, but also poses challenges in managing data pipelines.
In this article, I would like to share our experience of migrating on-prem data infrastructure to the Google Cloud Platform. We will explore how Google Cloud Composer functions as a process orchestrator and how this advanced platform supports enterprises in expanding their data potential, enabling them to adapt to modern business requirements effectively. Let's start by analyzing the old architecture.
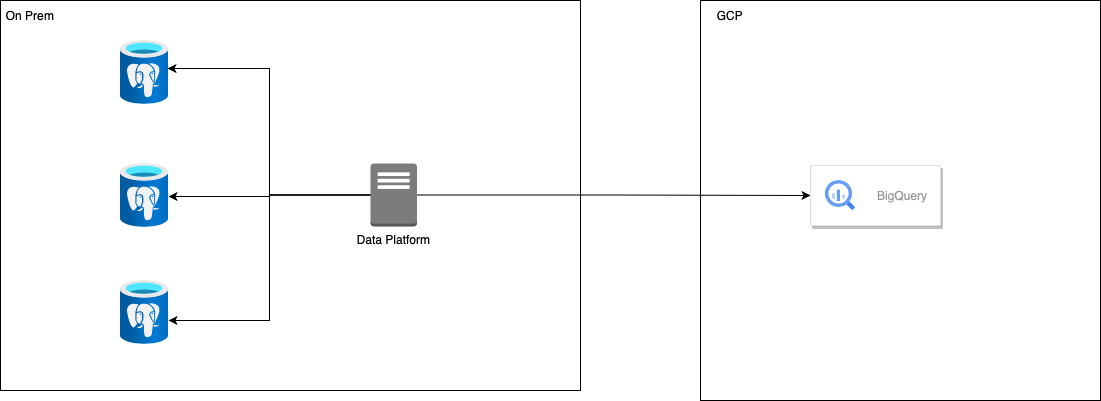
In the past, the organization used an on-premises data platform with various limitations. These limitations led to several challenges for the company, particularly regarding traditional infrastructure. While working on the on-premises data platform, the client had to deal with many complex issues that hindered the efficiency and agility of their data operations. Let's take a look at the diagram of the old architecture and then analyze its weakest points.
1. Bare-Metal Struggles: Running Data Pipelines on Physical Servers
The client grappled with the archaic practice of executing data pipelines on bare-metal servers. As a result, it led to suboptimal resource utilization and posed a significant challenge in scalability and platform maintainability.
2. Perils of Server Failures: Risk of Data Loss Looming
The looming threat of server failures added a layer of complexity to the on-premises setup. In the event of a server crash, the client faced the potential loss of critical data, highlighting the vulnerability of their existing infrastructure.
3. Cron-based Chaos: Data Pipelines Orchestrated by Cron
The reliance on Cron for scheduling data pipelines caused problems orchestrating complicated data pipelines. Moreover, running Cron and data pipelines on the same server caused problems with the solution's reliability, especially in resource-intensive calculations.
4. Monitoring Void: The Absence of Proactive Oversight
One of the main issues was the need for a robust monitoring system. The client needed real-time insights into their data pipelines' health and performance, thanks to which the response to incidents could have been much faster.
5. Manual Deployment Dilemma: New Data Pipelines Entailed Manual Effort
Introducing a new data pipeline required manual intervention on the server, a process fraught with inefficiencies and was prone to errors. This manual touchpoint hindered the swift deployment of innovative solutions and updates.
6. Scaling Stumbling Blocks: Manual Configuration for Platform Expansion
Scalability proved to be a manual ordeal, demanding the laborious configuration of new servers. This lack of automated scaling capabilities impeded the client's ability to adapt swiftly to changing data processing demands.
7. Onboarding Ordeal: Challenges in Welcoming New Analytical Teams
Onboarding new analytical teams became a formidable challenge due to the intricacies of the on-premises platform. The absence of streamlined processes made integrating new teams a time-consuming and complex task.
8. Access Management Abyss: Lack of Data Platform Access Controls
The absence of robust access management in the on-premises environment posed security risks. The client struggled to enforce fine-grained access controls, leaving their data vulnerable to unauthorized access.
9. Containerization Conundrum: Missing Dockerization Challenges Data Pipelines
The absence of containerization exacerbated problems in managing dependencies. Data pipelines, requiring various versions of dependencies, became a logistical headache without the encapsulation benefits offered by containerization.
10. Data Access Dilemma: Challenges in Accessing On-Prem Database Data
Accessing data stored in on-premises databases presented challenges, especially concerning data warehousing. The client's shift to leveraging BigQuery for data processing faced some hurdles, including soaring costs associated with Scheduled Queries.
11. Data Governance Gap in On-Prem Architecture
The client encountered a significant problem in their on-premises setup due to the need for more effective data governance, particularly regarding data lineage. The need for more transparency in tracking data flow put data quality at risk, hindered compliance efforts and introduced ambiguity into decision-making. Moving to the new architecture became essential for improving operational efficiency and addressing foundational issues, including integrating a comprehensive data governance framework.
In the evolving data management landscape, these challenges underscore an organizations' need to transition towards modern, cloud-based solutions such as Google Cloud Composer and Google Cloud Run, which remedy the pitfalls of traditional on-premises architectures.
In the ever-evolving landscape of data management, embracing a cutting-edge approach becomes paramount in overcoming challenges and unlocking the full potential of data platforms. Our journey with Google Cloud Composer has redefined our data architecture and addressed various pain points, ushering in a new era of efficiency and flexibility.
1. Data Pipelines on GCP Cloud Run: Unleashing Agility
One of the transformative shifts in our architecture involves the deployment of data pipelines on GCP Cloud Run. This move has enhanced the agility of our data workflows and allowed us to scale and execute tasks seamlessly, making our data processing pipeline more responsive than ever before.
2. Geo-Distributed Data Storage: Mitigating Data Loss Risks
By storing data in multiple geographic regions and setting up highly resilient Composer deployment, we've significantly reduced the risk of data loss. This geo-distributed approach ensures data redundancy, enhancing the resilience of our data platform and providing a robust safeguard against unforeseen incidents.
3. Airflow-Powered Pipeline Scheduling: Precision and Reliability
Scheduling data pipelines with Airflow has been a game-changer. The orchestrated workflows ensure precise execution timing, optimizing resource utilization and guaranteeing the reliability of our data processing tasks.
4. Comprehensive Monitoring with GCP Cloud Monitoring: Setting SLOs and Budget Alerts
Our commitment to a fully monitored platform led us to leverage GCP Cloud Monitoring. Setting Service Level Objectives (SLOs) and receiving notifications on budget utilization and errors ensures proactive management, allowing us to maintain optimal performance and cost efficiency.
5. CI/CD Revolution: Rapid Deployment with Cloud Build
Adopting Cloud Build for our end-to-end CI/CD process has streamlined the deployment of changes. We can implement new features and improvements within minutes, ensuring a nimble and responsive development cycle.
6. Scalability Made Simple: Leveraging Managed Services
The seamless integration of managed services into our data platform architecture has simplified scalability. Whether scaling compute resources or storage, the platform adapts to changing demands, ensuring optimal performance and resource efficiency.
7. Effortless Onboarding: Centralized Project with Composer
Onboarding new analytical teams has become a breeze, thanks to a centralized project structure with Composer. The modular approach allows for a quick setup of analytical projects, enabling teams to start work within minutes.
8. Robust Role Management: Native GCP Mechanisms
Managing roles and permissions is a breeze with native GCP mechanisms. This granular control ensures that access is precisely defined, maintaining the integrity and security of our data platform.
9. Containerized Pipelines on Cloud Run: Dependency Management Solved
Running data pipelines in containers on Cloud Run has resolved dependency management challenges. Each pipeline operates independently, eliminating conflicts and providing a clean, efficient execution environment.
10. Data Fusion Integration: Bridging On-Premises and BigQuery
The introduction of Data Fusion has facilitated seamless synchronization between on-premises databases and BigQuery. This integration simplifies data movement and accelerates our data processing capabilities.
11. Streamlining Google Sheets Data Transfer with GCP Composer
In the realm of data integration, Google Cloud Composer emerges as a powerhouse, simplifying the movement of information across platforms. Specifically, its prowess shines when seamlessly loading data from Google Sheets into BigQuery. This orchestrated process not only automates the mundane but ensures real-time data updates, enhancing the agility of your analytics. Explore the synergy of efficiency and automation with Google Cloud Composer, ushering in a new era of data-driven decision-making.
12. Data Governance with Google Dataplex
Google Dataplex has addressed the problem with Data governance. Dataplex is a tool that helps to organize and manage data from different sources in one place. It makes it easier to keep track of data and control who can access it. With Dataplex, you can also run checks to ensure the data is accurate and up-to-date and explore it using easy-to-use tools. Dataplex is a valuable solution for businesses that must manage large amounts of data from different sources.
In conclusion, our adoption of Google Cloud Composer has empowered us to build a data platform that is not only robust and scalable, but also highly adaptable to the dynamic needs of our organization. The new architecture marks a significant leap forward in our data architecture, setting the stage for continued innovation and optimization.
Our exploration of Google Cloud Composer reveals a paradigm shift in our data architecture, addressing challenges and unlocking new possibilities. The adoption of GCP Cloud Run injects agility into our workflows, while geo-distributed data storage enhances resilience against data loss risks.
Strategic use of Airflow for pipeline scheduling and GCP Cloud Monitoring for comprehensive insights ensures precision and proactive management. Cloud Build accelerates our CI/CD process, promoting a responsive development cycle.
Seamless scalability, effortless onboarding, robust role management and containerized pipelines on Cloud Run streamline operations. Data Fusion integration bridges on-premises and BigQuery, amplifying data processing capabilities.
Our migration to GCP Composer essentially empowers us with an adaptable and scalable future-ready data platform. With this foundation, we can navigate the evolving data landscape, poised for continued optimization and innovation. GCP Composer is our compass, guiding us towards a data-driven future.
If you need any help with designing a data platform architecture or moving from on-prem to the Cloud, then sign up for a free consultation with one of our experts: Free Consultation.
The year 2020 was full of challenges in many areas, and in many companies and organizations. Often, it was necessary to introduce radical changes or…
Read morePlanning any journey requires some prerequisites. Before you decide on a route and start packing your clothes, you need to know where you are and what…
Read moreCSVs and XLSXs files are one of the most common file formats used in business to store and analyze data. Unfortunately, such an approach is not…
Read moreThe adage "Data is king" holds in data engineering more than ever. Data engineers are tasked with building robust systems that process vast amounts of…
Read moreAt GetInData we use the Kedro framework as the core building block of our MLOps solutions as it structures ML projects well, providing great…
Read moreRecently I’ve had an opportunity to configure CDH 5.14 Hadoop cluster of one of GetInData’s customers to make it possible to use Hive on Spark…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?