Build a Data Lake to better manage your business data and get meaningful insights
Get meaningful insights for your business by collecting, transforming, and storing your data in one place. With Data Lake implementation you will gain freedom of combining structured and unstructured data from different parts of your organization and unlock the power of big data analytics. Whether you deploy it leveraging your IT infrastructure or using public cloud services, Data Lake solutions will surely help you manage your data.

They get value from Data Lake Platform:




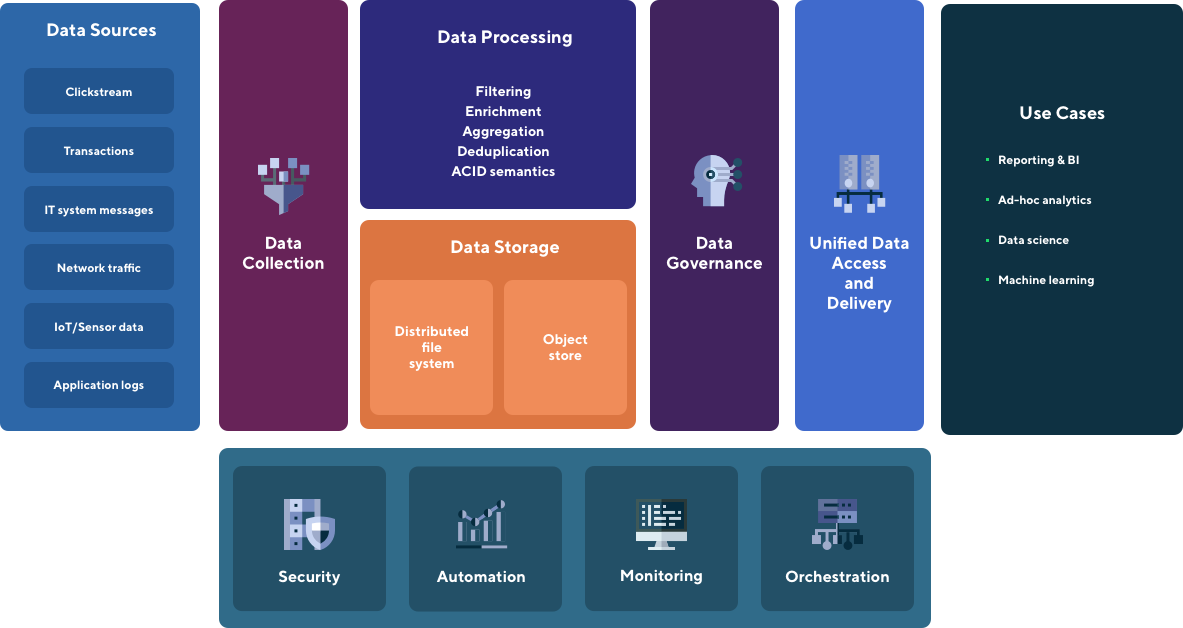
How does the Data Lake Platform work?
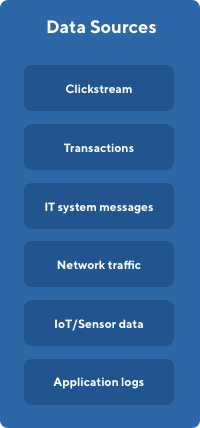
Data Source
Your IT systems exchange vast amount of information, that includes technical messages about opening a form on your website, network traffic information, sensor data, but also more meaningful information like new orders from your customer.
You obviously have access to most of that information in dedicated systems, in a more aggregated manner and on-demand. However, what would you do if you had a chance to combine messages from different systems and analyse them altogether in one place?
Data Lake is designed to collect various types of data in its natural form, transform them to the most usable and consistent state and store in an optimised way so you can further decided where and how you can benefit from them.

Data Collection
Data Collection pipelines are designed to continuously and incrementally load data from various sources like transactional databases, application log files, messaging queues, IoT APIs, flat files. This can be a clickstream from your website, transaction data from your main system, operational messages from other systems, application logs or IoT readings. Thanks to incremental loading and change data capture (CDC) we are able to load only data changes and optimize processing time.
We design our pipelines with Data Ops principles in mind - our code is always versioned, thoroughly tested, including data quality testing, and we use configuration management for simpler deployment.
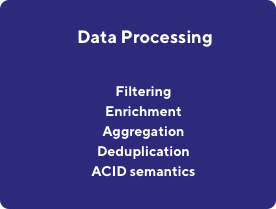
Data Processing
Allows you to perform data computations with frameworks like Apache Spark and prepare data for further analysis. Data processing includes various operations on data, like enrichment, while initial set is extended with external information, filtering, aggregation or deduplication.
ACID semantics is an interesting feature that allows to execute update and delete operations on data, so we can 1-to-1 images of data source, through incremental change data capture operations. Thanks to that we can reflect all changes in data in the further consumers of data - e.g. reports, dashboards, data marts.

Data Storage
This is a module where your structured (like transactions from ecommerce system), semi-structured (e.g. XML or JSON files) and unstructured data (these can be images, but also documents) is securely stored in a way that it can be accessed for further processing. Technically data can be stored on HDFS provided by Hadoop or object store deployed on-premise or in public cloud.

Data Governance
It provides information on who has access to your data and how your data is being used. One of the most important concepts around governance is data lineage, which gives you an ability to track where certain data is being used in your information ecosystem and is a key component of GDPR compliance. Implementation of both components can secure your audit needs.

Unified Data Access and Delivery
Data Lake is designed to provide an access to raw or aggregated data to different consumers, like reporting tools, visualisations, analytics. Data Scientist have one unified way to access data for their analysis and research, taking into account implemented data governance model. They do not need to copy data from different sources to work on them. If needed data processing can trigger actions in external tools, e.g. report refresh when certain extract is ready.

Security
Security and access management tool allows to control user access to data and components of the environment. It provides audit capabilities for verifying who has access to specific resources.

Automation
Deployment automation with proper configuration management are key to ensure the high quality of software delivery and to reduce risk of production deployments. All our code is stored in version control system. We design tests to be a part of the Continuous Integration and Continuous Deployment pipelines.

Monitoring
Complex monitoring and observability solution gives detailed information on the state and performance of the components. You can also deploy metrics to observe application processing behaviour. Monitoring includes also alerting capabilities, needed for reliability and supportability.

Orchestration
Originally all of the components of Hadoop ecosystem were installed with Yarn as an orchestrator to achieve scalability and manage infrastructure resources. Nowadays Kubernetes is becoming a new standard for managing resources in distributed computing environments. We design our applications and workloads to work directly on Kubernetes.

Data Consumers
Data Lake is a perfect solution if your organization is producing a large amount of data and you want to combine them in your reporting and analytics - this also covers semi-structured or unstructured data that probably you would not be able to analyse in traditional data warehousing solutions. Actually the fact that you can access the same data by different tools for different purposes (reporting, real-time processing, data science, machine learning) is the biggest value for organizations. It is especially useful for data scientists and analysts to provision and experiment with data gathered from the whole organisation.
In many organizations Data Lake is also a long-term storage solution for offloading transaction processing systems and historical data storage.
How does the Data Lake Platform work?
What is Data Lake?
You can say that Data Lake is storage, an infrastructure that helps you analyze your data faster and more efficiently. Thanks to the data Data Lake solutions, you can prepare those data for further use, for example in Machine Learning. A unified way to access data facilitates Data Scientists’ analytics and research process by giving them access to all data from one interface. If your organization produces large amounts of data and you need to use them in analytics and reporting, Data Lake is a solution for you.
How Data lake can benefit your business
Data Lake can be an efficient Big Data solution for your business, providing constant access to huge amounts of organizational data. Below are several possibilities of using Data Lake, including for real-time analytics or preparing the ground for technological changes. It can also become powerful support for your Data Scientists team.
Real-time analytics
Data Lake will allow you to use tools that can process huge amounts of raw data, so your organization will be able to make data-driven decisions based on real-time data analytics.
Scalability
Thanks to properly designed processing pipelines Data Lake solutions help to reduce data processing time and deliver your data product on time to your users
Data availability
Data Lake solutions ensure that everyone in the organization has quick but manageable and secure access to all the data they need.
Extracting quality data
Thanks to the implementation of DataOps principles solutions, the organization can control and improve the quality of its data.
Versatility
Multiple sources and diversity of data? With Data Lake tools you will be able to use every information you need for your business.
Data discovery
Whatever data your Data Scientists are looking for, Data Lake storage with data exploration tools will allow them to access data they need at any time.
Preparing for future changes
In an ever-changing Big Data technology environment, preserving raw and historical data makes it available to use with new tools and future analytics contexts.
Security and lineage
With one security model implemented for the whole platform and data lineage implemented for processing and querying data you can control the access to your data for security and audit purposes.
Get Free White Paper
Read a White Paper where we described a monitoring and observing Data Platform in case of continuously working processes.

How we work with customers?
We have a different way of working with clients, that allows us to build deep trust based partnerships, which often endure over years. It is based on a few powerful and pragmatic principles tested and refined over many years of our consulting and project delivery experience.

Your use case

Technical assessment

Solutions proposal

Production-grade solution

Discovery phase

Shared Teams

Extensions

Handover
- Read More

Big Data for Business
If you are interested in how we work with clients, how we develop the project and how we take care of the smallest details, go to the Big Data for Business website.
There you will learn how our Big Data projects can support your business.
- Read More

Knowledge base
We are happy to share with you the knowledge gained through practice when building complex Big Data projects for business. If you want to meet our specialists and listen to how they share their Big Data experiences, visit our knowledge library!
Ready to build your Data Lake?
Please fill out the form and we will come back to you as soon as possible to schedule a meeting to discuss about GID Platform
What did you find most impressive about GetInData?