Single interface for all your Data Science needs
Give your Data Scientists the freedom of choosing from a wide variety of Big Data and analytics tools and gain the meaningful insights you need. The Data Science Platform together with Data Discovery will make it easy to discover perfect data sets for the analytics task you are about to start.

They get value from Data Science Platform:


How does the Data Science Platform work?
Data Source
Your IT systems exchange vast amount of information, that includes technical messages about opening a form on your website, network traffic information, sensor data, but also more meaningful information like new orders from your customer.
You obviously have access to most of that information in dedicated systems, in a more aggregated manner and on-demand. However, what would you do if you had a chance to combine messages from different systems and react on the spot, just after they were generated? Event processing system are designed to analyse messages in real-time, enrich them with external information, combine into more complex events, analyze for patterns and trigger actions.

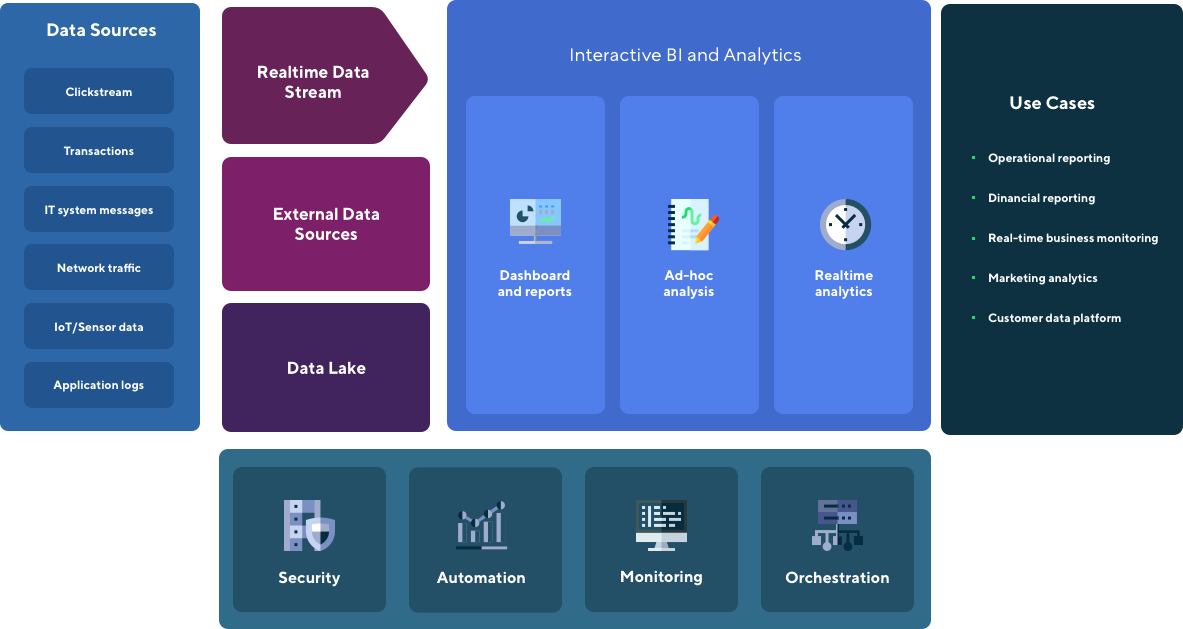
Realtime data stream
The business value of information decreases over time. It may be useful for your use case to analyse data in real time, so you can monitor your business activities and react on the spot.

External data sources
It may happen that you want to use data that is not available in your Data Lake. Our design allows you to access data from multiple systems, like external databases, files and data stores, within a single query. You do not need to copy data from different sources to use them in your report.

Data Lake
Data Lake is a place where your structured (like transactions from ecommerce system), semi-structured (e.g. XML or JSON files) and unstructured data (these can be image, but also documents) data is loaded and made accessible for reporting and analytics purposes. Data is stored in a secured manner, what means it can be only accessed by authorised users, and in optimized data structures for performance reasons.
Unified Data Science and ML

Data Science/ML Notebooks
Notebooks became a standard interface for Data Scientist to work with data. They are interactive web-based development environments where you can combine data from different sources, use various technologies and visualise output. Notebooks are very open and flexible - they can be configured to support wide range of workflows in data science, scientific computing and machine learning. Standard functionalities can be extended by existing or custom plugins. There is also a wide variety of visualisation libraries available for static and interactive plots. Notebooks give freedom to choose tools that are the most appropriate to the task, they structure research and make it easy to share with peers. The list of supported technologies is long, just to mention a few: Python, R, Julia, Ruby.

Interactive BI
Interactive BI allows to explore data verify hypothesis regarding data insights. Using interactive tool you will be able to connect to Data Lake or other data sources - they all create a federated data source that you can query no matter where data is physically stored. Data can be reported on demand or on a scheduled basis.

Data Discovery
Data Discovery component should be the first step in data analytics. Its main goal is to improve productivity of data analysts and data scientists. In simple words this is the catalogue of all available data sets that you can use in your work. Data sets are searchable, have descriptions, popularity score, quality metrics and domain knowledge experts defined. You can easily find the most promising data sets and check with your peers who have more experience working with it.

Security
Security and access management tool allows to control user access to data and components of the environment. It provides audit capabilities for verifying who has access to specific resources.

Automation
Deployment automation with proper configuration management are key to ensure the high quality of software delivery and to reduce risk of production deployments. All our code is stored in version control system. We design tests to be a part of the Continuous Integration and Continuous Deployment pipelines.

Monitoring
Complex monitoring and observability solution gives detailed information on the state and performance of the components. You can also deploy metrics to observe application processing behaviour. Monitoring includes also alerting capabilities, needed for reliability and supportability.

Orchestration
Originally all of the components of Hadoop ecosystem were installed with Yarn as an orchestrator to achieve scalability and manage infrastructure resources. Nowadays Kubernetes is becoming a new standard for managing resources in distributed computing environments. We design our applications and workloads to work directly on Kubernetes.

Use cases
The need of having proper reporting in your business is rather indisputable. However having a unified access to all your data and being able to combine data in a single report from different sources might bring your analytics capabilities to a higher level. Access to proper technology will not only increase your Team productivity but also improve reliability and consistency of your reporting. It is also a foundation for becoming a data-driven organisation.
How does the Data Science Platform work?
What is Data Science Platform?
Data Science Platform is a set of tools, intended mainly for Data Scientists, thanks to which they have unified access to all data sources and can employ tools of their choice to perform their work more effectively. It uses a common interface, provides data discovery solutions, and enables work sharing for better collaboration and quality work.
Data Science Platform For Business - how can it help your organization?
Below we present the possibilities of implementing the Data Science Platform. Thanks to this tool, the work of your Data Scientists will be easier, the research process will be significantly improved. It can also improve communication and cooperation between your Big Data team and external entities.
Minimize Engineering Effort
Thanks to Data Science solutions, your Data Scientist won’t need DevOps support to develop and implement data models.
Faster Research
thanks to the transparency of activities on the Data Lake Platform, Data Scientists can see the activities of other stakeholders, which reduces the time of data management.
Reduce the number of low-value tasks
Thanks to tools used by Data Lake platform, Data Scientists are free from tasks that would otherwise take up too much time, such as reproducing reports or preparing environments for non-technical members of the organization.
Better collaboration
Better cooperation between your Data Scientists and with external entities significantly increases the productivity of your Big Data team.
Better quality
having single access to data ensures accuracy and consistency of analysis
Get Free White Paper
Take a look at some of the big data projects delivered by our big data expert team

How we work with customer?
We have a different way of working with clients, that allows us to build deep trust based partnerships, which often endure over years. It is based on a few powerful and pragmatic principles tested and refined over many years of our consulting and project delivery experience.

Your use case

Technical assessment

Solutions proposal

Production-grade solution

Discovery phase

Shared Teams

Extensions

Handover
- Read More

Big Data for Business
If you are interested in how we work with clients, how we develop the project and how we take care of the smallest details, go to the Big Data for Business website.
There you will learn how our Big Data projects can support your business.
- Read More

Knowledge base
We are happy to share with you the knowledge gained through practice when building complex Big Data projects for business. If you want to meet our specialists and listen to how they share their Big Data experiences, visit our knowledge library!
Ready to build your Data Science Platform?
Please fill out the form and we will come back to you as soon as possible to schedule a meeting to discuss about GID Platform
What did you find most impressive about GetInData?