Tutorial
Power of Big Data: Science
Welcome to the next installment of the "Big Data for Business" series, in which we deal with the growing popularity of Big Data solutions in various…
Read moreReal-time analytics are all processes of collecting, transforming, enriching, cleaning and analyzing data to provide immediate insights and actionable information. It enables the user to access data and create dashboards that will be updated in real-time. Which means that all changes will be shown immediately, not daily, not weekly, but ‘now’, enabling the user to make data-driven decisions. In this blogpost we will discuss the potential and possible applications of Real-time Analytics and its advantage over batch processing. We will dive into the Real-time Analytics architecture so that you will know how it works, and what mechanisms drive it. You will also learn about the technologies and Real-time Analytics limitations and alternatives, so you can decide if it’s the best solution for your organization. We will also have a look at a real-life example from the e-commerce industry.
Traditionally, all analytics work used to be done as batch jobs, usually executed hourly or even just daily. This approach has been common for years, and is quite easy to implement and maintain. It is much easier to achieve stability and consistency using batches. Yet in today's fast-paced and data-driven world, a traditional approach is often not enough. Many industries require and rely on fast, near real-time metrics calculations, automated decision-making, or other reactions to events. This is especially important in customer-facing analytics.
Customer-facing analytics brings BI capabilities directly to end users, often inside already existing or custom applications. It provides self-service possibilities where users can gain insights themselves, without building complex queries. One of the main user-facing analytics characteristics is the need for handling many concurrent queries.
The key characteristic of real-time analytics is the ability to analyze data in near-instantaneous time, allowing organizations to make timely decisions, respond quickly to changing conditions, gaining a competitive advantage. This can be very beneficial, or even the bread and butter for the following industries:
Financial Trading - enabling the making of quick decisions to execute a buy or sell based on market fluctuations,
E-commerce - for offering personalized recommendations, adjusting pricing strategies and managing inventory efficiently,
Internet of Things - for analyzing vast amounts of data to derive meaningful insights
Cybersecurity - for identifying unusual patterns and detecting potential security threats
Telecommunications - for identifying issues and optimizing the allocation of resources.
This list only presents selected examples but in practice, we can find many more applications for its use.
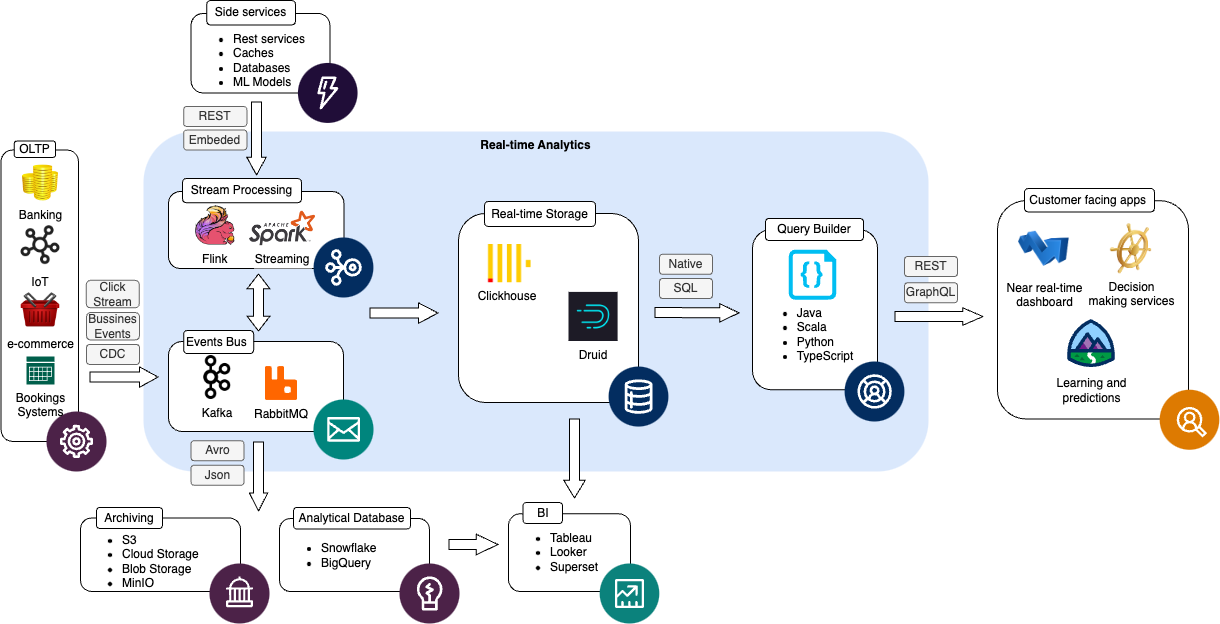
The following diagram represents the architecture that we quite often see and offer our clients:
By describing data flow in the core of the system, we can distinguish the three main parts involved in Real-time analytics:
This is about how data is prepared to be ready for analytics queries. It includes ingestion, cleaning, enrichment and transformation for creating performance-driven data models that make it possible to query the necessary performance. This component strongly cooperates with and relies on messaging systems that are used for communication between other components.
The heart of the system is the Analytical Database. It is responsible for processing huge amounts of data to aggregate and calculate necessary metrics in the lowest possible latency.
A lightweight layer that is a proxy to accessing data. It is usually created as a Microservice or library that is responsible for building optimal queries in SQL or using another native language. Most often it is necessary to expose clear and consistent APIs for external custom applications to reach the data optimally.
Other components that can be observed in the picture:
Usually, these are OLTP systems that are responsible for handling client business and are strongly related to the industry that Real-time analytics is prepared for. Data delivered to the system can have a variety of purposes and formats, and can be delivered using different protocols. The most common types are:
As a Real-time analytical system server's purpose of quickly delivering information on up-to-date metrics and company performance, some areas can benefit from the same collected and prepared data. An example can be training machine learning models, preparing offline reports or analyzing raw data on the whole history. This processing requires a lot of resources and shouldn’t use the same resources as Real-time analytics, which are more expensive and available 24x7. Also, a heavy load on Real-time storage may disturb standard usage. To solve this problem, we strongly recommend the integration with another system that is more suitable for processing data in batches. This way we can decrease the costs of the whole system and increase its stability, whilst providing much more functionality.
Data preparation usually requires an enrichment process or transformation, based on the external metadata that comes from other systems. This can be applications, caches, databases or machine learning models. You can read more about training and deploying models in our other blog posts.
BI tools can directly connect to Real-time storage and provide quick report calculations without using intermediate caches.
As we can support most of the well-known streaming frameworks, we strongly recommend using Apache Flink. Flink is a powerful distributed data processing framework. It has built-in advanced support for event-time processing, which is essential for handling out-of-order events in streaming data. This allows Flink to handle real-world scenarios where events may not arrive in the order they occurred.
Flink is designed with low-latency processing in mind, making it suitable for use cases that require real-time or near-real-time analytics. This is in contrast to the very popular Apache Spark, which uses micro-batching and introduces some latency.
Flink provides native support for stateful processing, allowing you to maintain and update the state across events and time. This is crucial for applications that require maintaining context over a period of time, such as session windowing.
Flink provides dynamic scalability which can be useful for handling varying workloads and adapting to changes in data volume.
Flink is very mature and well-battle-tested in many production environments. Even though other popular frameworks support similar capabilities, Flink's implementation is often considered more advanced.
It is hard to imagine Streaming processing without a fast and reliable event bus. Our architecture and components can cooperate with most of the popular messaging systems, but similarly to Flink, we recommend one over others to our customers. Our choice is Apache Kafka as a distributed system with strong durability guarantees. It doesn’t have competitors in terms of throughput and ease of scalability combined with maturity and production readiness.
At the time of writing this article, we had knowledge of and experience with two Real-time storages: Clickhouse and Druid. Both are high-performance real-time analytics databases. Both use a columnar format which makes them perform much better than other databases, support data partitioning and pre-aggregation and rollups. Both systems provide low latency and fast aggregation for even billions of rows. Both systems serve similar purposes, yet Druid seems better in terms of using data that was just inserted (which Cickhouse doesn’t guarantee) and tends to be more event-based, while Clickhouse prefers to process data in micro-batches (inserts, materialized view etc.). Unfortunately, it doesn't come without its problems. Druid is more costly to support and maintain as it requires more machines and granular components.
The proposed solution also has its limitations. The online world always has many more rules, constraints and issues to solve. For a performance-driven approach, we need to sacrifice some good practices or clean readable data structures to lower latency and resource consumption. An example can be data model denormalization, which is less readable for humans but provides way better performance than stars-schema.
One may ask ‘why not use the pure (near) real-time approach’? By using appropriate frameworks and programming languages, we can create any transformation imaginable. This is actually true, and stream processing is an integral part of the proposed solution, yet it is often not enough. The biggest problem with this is data aggregation. Usually, we are not able to predict dimensions, date ranges or even metrics that should be calculated online. In the same way that Data Lakes provide the flexibility of defining insight calculations later, Real-time analytics gives us the possibility of attaining the dimensions later on.
Another well-known technique in providing real-time analytics capabilities is working out the possible calculations upfront and then only querying the results. This is a good approach whenever we can predict dimensions and metrics. It is usually used if we know exactly which timeframe our users are interested in, for example, monthly reports. This way we can significantly lower the required resources and costs of the system. Unfortunately in most cases, the number of combinations of all possible dimensions is so big, that implementation and maintenance make no sense.
In most demanding environments, the best results can be achieved using a combination of different techniques described in this article.
In this section, I will describe an example system that we recently developed for one of the startups in the e-commerce industry.
Our client provides Real-time analytics capabilities for online stores. He tracks all client users' activities and provides useful metrics and reports on how the business is going and how to manage and improve the KPIs.

The mainstream of data comes directly from the users' browsers as clickstream. It is pushed by a simple proxy to the Kafka topic in the original format. The next step is processing this data by a Flink job, which is responsible for enrichment (eg. with predicted values from machine learning models), transformation (eg. by calculating user sessions by windowing) or joining with different streams to get a semi-denormalized structure. The prepared data is then sent back to Kafka and ingested by Clickhouse. Clickhouse uses its connector and materialized views for further data enrichment, transformation and pre-aggregations. The reason for keeping some processing logic in Clickhouse is that some of the data inserted by Batch jobs are already available and easily accessible from the storage itself, rather than by external jobs. The last component is Query Builder, responsible for creating optimal SQL requests to the database using appropriate keys, partitions and data distribution.
If you want to learn more, feel free to talk to our experts about the possibility of implementing real-time analytics - sign up for a free consultation.
Welcome to the next installment of the "Big Data for Business" series, in which we deal with the growing popularity of Big Data solutions in various…
Read moreWhile a lot of problems can be solved in batch, the stream processing approach can give you even more benefits. Today, we’ll discuss a real-world…
Read moreOne of our internal initiatives are GetInData Labs, the projects where we discover and work with different data tools. In the DataOps Labs, we’ve been…
Read moreHow to minimize data processing latency to hundreds of milliseconds when dealing with 100 mln messages per hour? How can data quality be secure and…
Read moreAbout In this White Paper, we described what is the Industrial Internet of Things and what profits you can get from Data Analytics with IIoT What you…
Read moreThe two recently announced acquisitions by Google and Salesforce in the thriving business analytics market appear to be strategic moves to remain…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?