Tutorial
How to predict Subscription Churn: key elements of building a churn model
Despite the era of GenAI hype, classical machine learning is still alive! Personally, I used to use ChatGPT (e.g. for idea generation), however I…
Read moreWelcome back to our comprehensive coverage of InfoShare 2024! If you missed our first part, click here to catch up on demystifying AI buzzwords and gamified security training. In this second part, we focus on the DataMass stage, which we co-organized and hosted, where industry leaders delve into the intricacies of data quality, AI-powered enterprise intelligence and innovative approaches to data management.
The effectiveness of LLMs and AI depends not only on the model itself. It would be worthless without high-quality data used in the training process. Without good data, it’s impossible to draw correct conclusions. Dennis Thomsen focused on this issue during his speech entitled “Data Quality - More than you think.” Let’s go through the key points of this presentation!
Data quality means:
Dennis presented two approaches to enssure data quality: active and passive data governance.
Active data governance is executed before data processing, correcting data in-flight or separating incorrect data from the correct. This may introduce latency to data processing or even halt it if processing incorrect data is not permitted.
Passive data governance focuses on validations and checks performed on already processed data. This approach deals with issues after they occur and commonly refers to aspects like:
The very first step in data quality is data profiling. It allows us to generate validation rules based on existing data scans. It can detect uniqueness, completeness, data range and allowed values, etc. For more details, please refer to solutions like Informatica Data Quality, Qlik Data Catalog or Microsoft DQ (preview).
An increasingly popular alternative approach is data contracts, which are agreements between producers and consumers describing data structure, format, validation and other rules.
Dennis emphasized that data profiling and validation is only the tip of the iceberg. To increase data consistency, it is worth considering comparing it with external systems or using probabilistic linkage data tools like Splink.
Not everything can be automated. Data quality may require more restrictive management of data inputters, power users who understand the impact of data, or even manual sampling and verification.
Remember - data quality is crucial!
Copilot is a great tool that speeds up coding, learning programming languages, testing and more. However, some companies have banned such tools to avoid problems with GDPR regulations and for other safety reasons. What can you do in that situation? Perhaps you could do with your own personal copilot, tailored to your company’s best practices and specific needs.
Marek Wiewiórka, Chief Architect at GetInData | Part of Xebia, presented a solution during his talk, "Enhanced Enterprise Intelligence with Your Personal AI Data Copilot." Marek identified a market gap in AI assistants focused on Text-to-SQL with dbt/SQL support. Such tools could greatly assist data analysts and data engineers in their daily tasks. Existing open-source tools like WrenAI, Venna.AI and Dataherald support Text-to-SQL but are designed for non-technical users, often providing their own editor or working as chatbots. Another category includes AI Assistants that function as non-customizable black boxes, dedicated to specific cloud solutions like BigQuery, Snowflake or Databricks.
Industry leaders suggest that customized and specialized models are the future. Indeed, many small open-source models (7-34 billion parameters) can compete in specialized tasks with commercial models like ChatGPT-4 (1.76 trillion parameters). Surprisingly, models like starcoder2 and Llama3 have outperformed ChatGPT-4 in generating SQL queries.
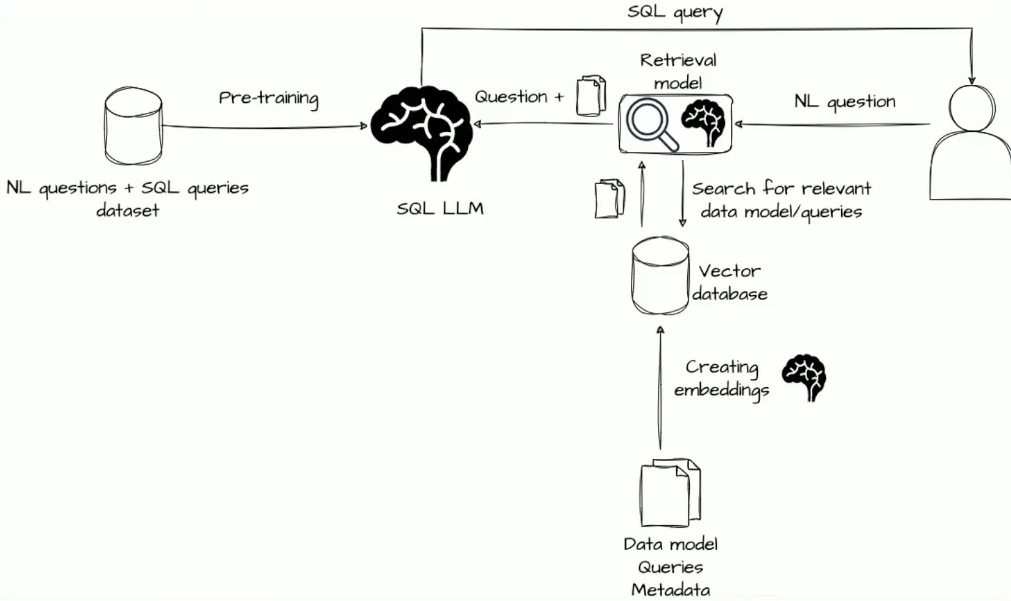
Once you have the appropriate language model(s), you can enhance it with Retrieval Augmented Generation (RAG) techniques. Remember—context is king! By providing a knowledge database with best practices and code standards, your copilot can generate well-suited responses. RAG uses a vector database with vector search, where each item is transformed into vector representations, known as embeddings. Vector search uses the approximate nearest neighbors (NN) algorithm to find proper matches. Since NN alone might not suffice (e.g., searching for 'orange'), it is often combined with a full-text search in a technique called hybrid search, which merges results using a customized re-ranker.
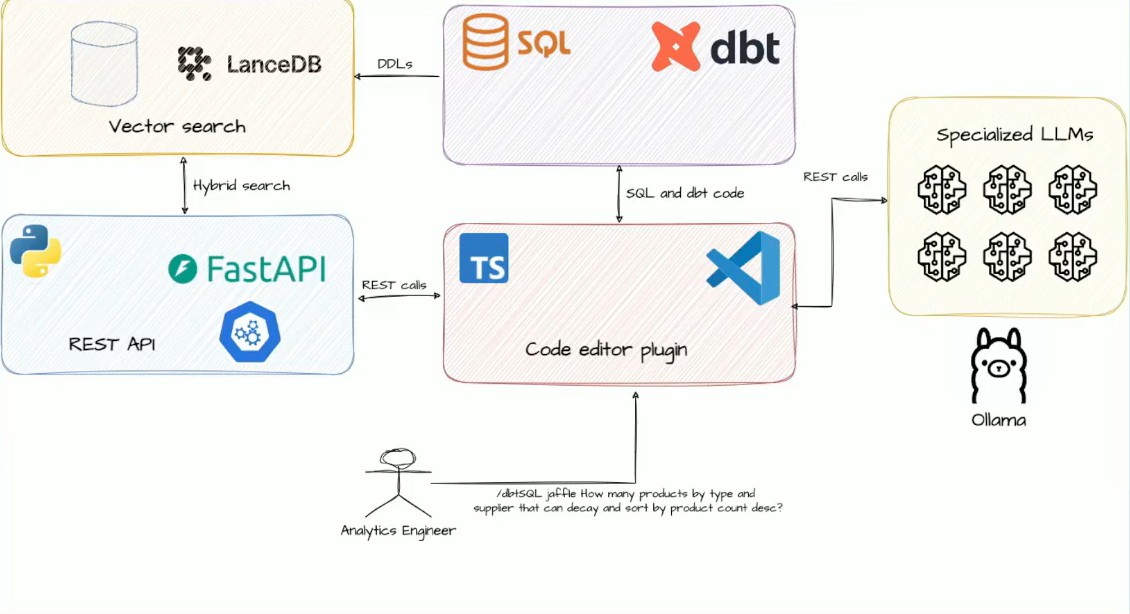
Armed with these concepts, you can start building your own AI assistant. Marek chose to use Continue, an open-source copilot. Continue supports both autocompletion and task management, can work with any LLM model (including multiple specialized models), and integrates with custom context providers (RAG). It can be integrated with VSCode and JetBrains and offers secure deployment options, running locally, on-premise or in a cloud VPC.
For model hosting, Marek used Ollama, which enables fast and easy self-hosting almost anywhere. Ollama has a rich library of existing LLMs and allows for importing new ones.
LanceDB was used for vector search. Written in Rust, LanceDB is fast, serverless, embeddable and supports hybrid search. The database was integrated with the copilot by a REST API created in the FastAPI library (Python).
The architecture is presented in the diagram below.
That's it! The GetInData data copilot is ready and can be used during daily work.
Marek conducted model evaluations, including comparisons with commercial models, on tasks such as model discovery, simple and complex SQL generation and dbt model and test generation. ChatGPT-3.5/4 and phind-codellama scored the highest, while other models struggled with dbt or more complex SQL tasks. Dbt test generation proved to be the most challenging task.
Text-to-SQL and dbt generation turned out to be particularly difficult tasks. While commercial models remain the best, there are very promising open-source SLM alternatives. Surprisingly, SQL-dedicated and fine-tuned models were somewhat disappointing.
Marek also played a short demo of GID data copilot that you can watch here.
He demonstrated that building your own copilot is not as difficult as it might initially seem. All the necessary components are available and can be easily integrated to suit your specific needs!
If you have questions and want to discuss the possibilities and benefits of data copilot in your business, fill out the form to schedule a free consultation.
When we think about data, we often focus on values, volume and velocity. However, the aspect of its structure is commonly neglected or underestimated. During his talk "Knowledge Graphs and LLMs: GraphRAG for Reliable AI", Jesus Barrasa from Neo4J explained why this is a misguided approach and how graph databases can improve Retrieval Augmented Generation (RAG).
The complexity of data relationships is often ignored, yet their value is as significant as the data itself. For example, consider money transfers between accounts. By building a chain of transactions, you can identify patterns that may indicate money laundering schemes. A star topology helps to easily identify critical network devices, while a cloud topology is useful for analyzing social communities and marketing campaigns. LinkedIn successfully uses a property graph database to connect users with colleagues from their previous companies.
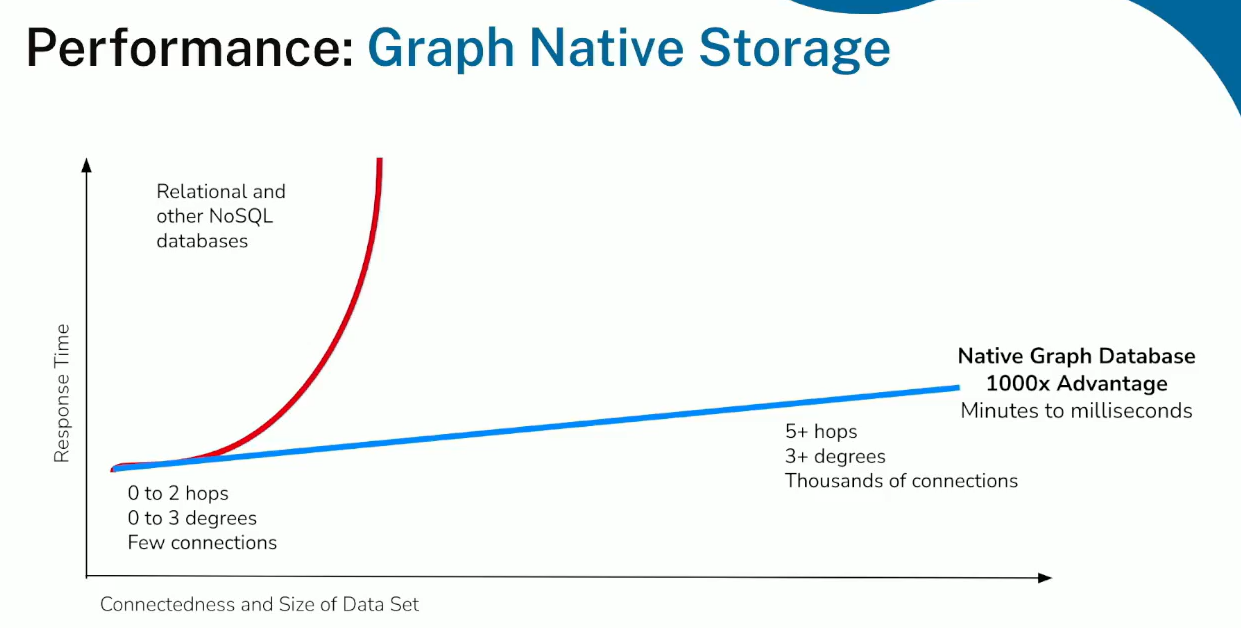
Jesus argues that a fundamentally new approach is needed. Data warehouses are useful but won’t identify bottlenecks in your supply chain that pose a risk to your business. While it's possible to model relationships in tables, the complexity of scanning is logarithmic and volume-sensitive. Graph-native databases offer linear query times that depend only on the search area, not the graph size.
Graph databases can process queries thousands of times faster than relational databases, and the queries require less code. GQL was standardized in 2024, marking a major milestone for graph databases.
How can graph databases empower AI? Let’s focus on RAG and vector databases. The common implicit (sub-symbolic) approach relies on embeddings with vectors and an approximate nearest neighbor search to capture data meaning and similarity based on vector distance. The explicit (symbolic) approach uses a knowledge graph, offering structural (e.g., node similarity, overlap, Jaccard) and taxonomic searches (e.g., path, Leacock-Chodorow and Wu-Palmer). Graph databases can directly identify that "orange" refers to a fruit, while a vector search might also classify that as a color. Furthermore, a graph search is explainable, allowing you to understand the context, unlike a vector search, which relies on unclear numerical values.
This doesn't mean the explicit approach is superior to the implicit one. Jesus presented a way to benefit from both. How does it work? A knowledge graph captures key enterprise knowledge in the form of entities and relationships. Some nodes in the graph have properties with natural language text, which can be embedded to enable a vector-based semantic search. By combining both techniques, you can narrow or expand the result set with relevant information from linked graph nodes, helping to prevent LLMs from hallucinations.
Jesus demonstrated this approach using documents with rich internal structures. While the vector-based RAG approach missed some important parts linked in the document, GraphRAG was able to use the connections to provide precise responses.
Relationships are key to deeper insights. A knowledge graph combined with generative AI enables you to build intelligent applications!
InfoShare 2024's DataMass stage was a treasure trove of practical knowledge, showcasing innovative solutions and best practices for data management and AI implementation. To stay ahead in the ever-evolving field of data and AI, subscribe to our newsletter and get the latest insights and updates from industry experts delivered straight to your inbox.
Make sure you revisit our first part of the InfoShare 2024 overview to catch up on all the groundbreaking discussions from the main stage. Don't miss out on the valuable information shared at this landmark event!
Stay in the loop on future innovations! Join our newsletter for exclusive insights and updates.
Despite the era of GenAI hype, classical machine learning is still alive! Personally, I used to use ChatGPT (e.g. for idea generation), however I…
Read moreLearning new technologies is like falling in love. At the beginning, you enjoy it totally and it is like wearing pink glasses that prevent you from…
Read more“Without data, you are another person with an opinion” These words from Edward Deming, a management guru, are the best definition of what means to…
Read moreCan you build an automated infrastructure setup, basic data pipelines, and a sample analytics dashboard in the first two weeks of the project? The…
Read moreEver felt overwhelmed by the flood of news about the latest technologies, tools, and trends in Data, AI, and ML? A new framework here, a revolutionary…
Read moreThe year 2023 has definitely been dominated by LLM’s (Large Language Models) and generative models. Whether you are a researcher, data scientist, or…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?