In the fast-paced world of data processing, efficiency and reliability are paramount. Apache Flink SQL offers powerful tools for handling batch and streaming jobs, but optimizing joins, state management and checkpointing can significantly enhance your job stability and performance. This guide will walk you through the best practices for achieving optimal performance with Flink SQL.
Flink SQL is a query and processing engine that accelerates the development of batch and streaming jobs. It handles tasks such as joins, aggregations, ranks, pattern matching and more, providing fault tolerance, robustness and scalability thanks to its stateful processing capabilities.
The state of a Flink job is continually evolving. At any given moment, the job's completed state is referred to as a checkpoint or savepoint. This feature allows you to restore a job from a checkpoint if it fails, similar to the mechanism in video games.
The checkpoint mechanism works by emitting periodic barriers that traverse the pipeline. When a barrier reaches a subtask, the operator's state is serialized and stored externally. A completed checkpoint contains state data collected from all operators, as well as in-flight data, and can be used for recovery, an upgrade or resuming a job.
Efficient and reliable checkpointing is crucial for job stability and performance. When implemented incorrectly, it can lead to decreased pipeline throughput, increased latency or even cause job failures and stop progress. In this article I will provide some hints on optimizing checkpointing, focusing on a sample job written in Flink SQL.
Checkpoints and first aid
By default, checkpoint barriers are synchronized with data processing, meaning that a checkpoint is considered complete only when the job has processed all the data buffered before the checkpoint barrier. However, this approach can be slow due to factors such as a complex pipeline built from multiple tasks in-line, IO operations, large buffers or data skew, which can limit job throughput and affect processing time from source to sink. In such cases, enabling unaligned checkpoints can be beneficial. An unaligned checkpoint allows the checkpoint barrier to overtake the data in buffers, storing them as part of the checkpoint as in-flight data.
If a job's state backend is managed by the RocksDB, enabling incremental checkpoints can also be advantageous. Incremental checkpoints minimize a serialized state by only keeping deltas between consecutive checkpoints. However, it's worth noting that enabling incremental checkpoints may impact job startup time. This is because of the need to rebuild a state from fragmented parts, which slows down the job's initialization phase.
Keep the state small
Are checkpoints failing because of the state size? Are your operations slow because of the time of accessing/writing to the state? Let’s optimize it!
Identify heavy operators
Flink provides lots of useful metrics for monitoring checkpointing and diagnosing issues. Let's start by identifying heavy tasks and operators. The easiest way to do this is by using the Flink UI. Navigate to the Checkpoints tab, where you'll find detailed information such as:
- Checkpoint type (aligned/unaligned): Flink always starts the checkpoint as aligned, but it will become unaligned if it exceeds the aligned-checkpoint-timeout and unaligned checkpointing is enabled.
- [Full] checkpoint data size: This includes the checkpoint size. In the case of incremental checkpoints (RocksDB only), you can compare delta and full data sizes.
- Processed (persisted) in-flight data: Unaligned checkpoints can overtake data to be persisted in the checkpoint, representing a trade-off between checkpoint time and IO operations.
- End-to-End Duration: This indicates the duration between releasing the barrier on the source and storing the operator's state.
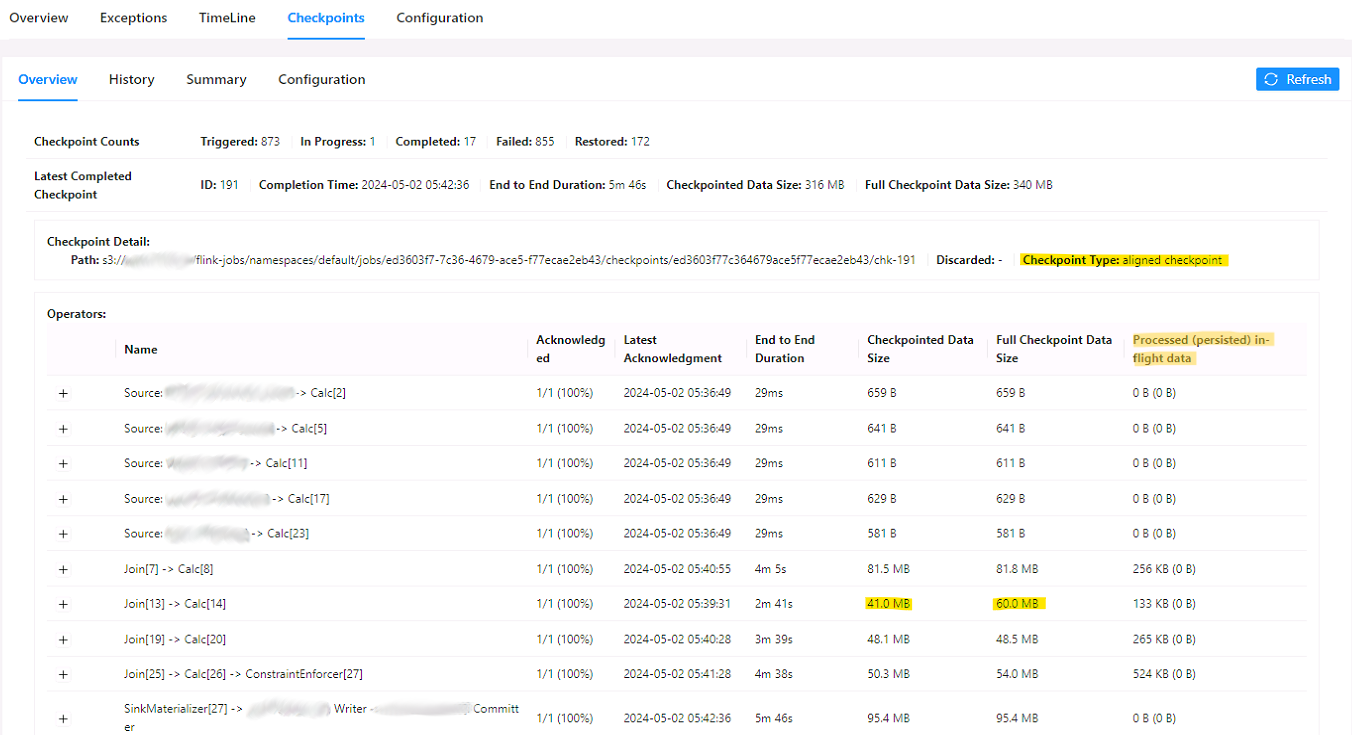
In the case of data skew issues, you may notice that some subtasks require more time to process checkpoint barriers, especially when using aligned checkpoints. Moreover, the state of these subtasks may be significantly larger. While this article focuses on checkpoint size, it's essential to note that data skew can also impact checkpointing.
Now that we know how to check the operators' state size, let's analyze the use case job.
Data enrichment job
The client requires a left join operation between the main table TABLE_A and 8 dictionaries (DICT_[1-8]), as well as outputs from another 3 Flink jobs (JOB_[1-3]). The desired outcome is denormalized data, suitable for storage in a warehouse for reporting purposes. This scenario represents typical data enrichment.
Below is a brief analysis of the input data, listed in the table:

Source: Indicates the source of the data.
- Kafka/Flink - Data produced by another Flink job as a changelog, stored by an upsert-kafka connector.
- Kafka/CDC: Data produced as change data capture (CDC), for example, by Debezium.
Incoming data rate level: Simplified rate level of incoming data.
Initial size/row count: The size/row count of the Kafka topic after loading the initial snapshot (CDC) or processing data by other Flink jobs.
Columns in table: Number of fields in the message’s schema/table’s column.
Required columns: Number of columns required for the job.
Requires the latest version - if updates have to be propagated to processed data (only for right side tables)
The first (naive) implementation - regular join
The initial approach is to utilize a regular join. This method is straightforward to implement: there are no restrictions on the join condition, and it does not require a watermark or data alignment. It can accommodate both one-to-one and one-to-many relationships. A unique characteristic of regular joins is their ability to generate events if changes occur on the right side of the join.
I have truncated DAG to highlight essential operators.

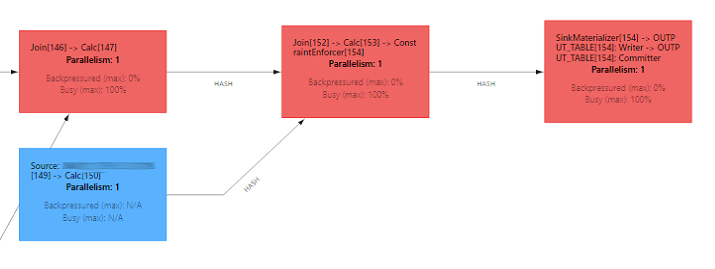
When examining state size metrics, I identified heavy operators:
- ChangelogNormalize
The upsert-kafka connector converts Kafka messages into a changelog stream. By using the primary key and state with processed messages, it can detect types such as Insert/Update/Delete and construct the UpdateBefore row. - Join
The regular join must maintain both the left and right side of the join in the state. It finds matches and releases joined rows. Particularly in scenarios involving one-to-many relations,this may lead to a data explosion when one event operator releases thousands of joined data.
Rows will be kept in state forever by default. However, this behavior can be modified using the table.exec.state.ttl parameter, which allows the state to clean up after a specified time. Beginning with Flink 1.18, the TTL can be configured on an operator-state level. With Flink 1.19, the introduction of the STATE_TTL sql hint further simplifies this process. It's important to use state cleanup with caution, as it can impact the data produced by the operator! - SinkMaterializer
This operator addresses race conditions between subtasks. While the algorithm is well-explained, it does have limitations. For example, it does not work with dynamic columns (e.g., CURRENT_TIMESTAMP). Additionally, it requires a full changelog stream with UpdateBefore events, a condition that cannot always be guaranteed by operators like temporal joins.
In my pipeline, I have 4 sources with ChangelogNormalize, which is particularly heavy only for TABLE_A. This largest table must be processed by each of the 11 joins. Finally, there is SinkMaterializer. As you can see, I have to maintain TABLE_A in 13 operators, resulting in roughly 780GB in state after processing initial data. This is just an estimate - some objects will be deduplicated, and I didn't take into consideration the other tables. The final size of serialized and compressed objects in RocksDB can be lower, but in total, it is still more than half a terabyte.
It’s possible to optimize such a pipeline by:
- Limiting columns on the source. Restricting the columns retrieved from the source can reduce the amount of data stored by ChangelogNormalize and processed downstream.
- Limiting joins with the largest table. Pre-joining smaller tables with the main table can minimize the number of joins involving the largest table. This can be achieved by creating views or using Common Table Expressions (CTEs) to join smaller tables before joining them with the main table.
- Smart order of joins in the query. Arrange the joins in the query to optimize performance. Flink-planner won’t do this for you! Since the output of each join needs to be processed by downstream operators, place the heaviest joins at the end of the sequence. This ensures that lighter operations are performed first, potentially reducing the overall computational load.
How did the job function? Initially, everything seemed fine: the buffers quickly filled with data, and the state began to grow. However, after the first hour, pipeline throughput significantly decreased, and checkpoints took minutes to complete. Handling the state consumed a considerable amount of CPU resources and became slow. Later the job started failing due to checkpoint timeouts and was unable to progress. Applied optimizations helped a bit, but they only postponed the timeouts. Did I mention that this behavior occurred after tuning RocksDB and checkpointing? Disaster!
Lookup join
The root cause of checkpointing timeouts is the large state of regular joins. Consequently, I conceived the idea of replacing them with stateless lookup join operators. But how does it work?
Lookup join enhances a table with data queried from an external store. It can be used to model one-to-one and one-to-many relations where there is no need to react to updates from the right side of the join. A dictionary table is a great candidate for a lookup join. It's a slowly changing dimension table, and data alignment shouldn’t be an issue. Consequently, values can be cached by the operator.
Lookup join offers several advantages. The join is executed in place, without any data shuffle, making it resilient to data skew issues. One of the most important benefits is that lookup join is a stateless operator.
I ingested dictionaries into a database, connected it with Flink, and built the job. SinkMaterializer was disabled (table.exec.sink.upsert-materialize) due to its limitations and replaced by the Rank function.
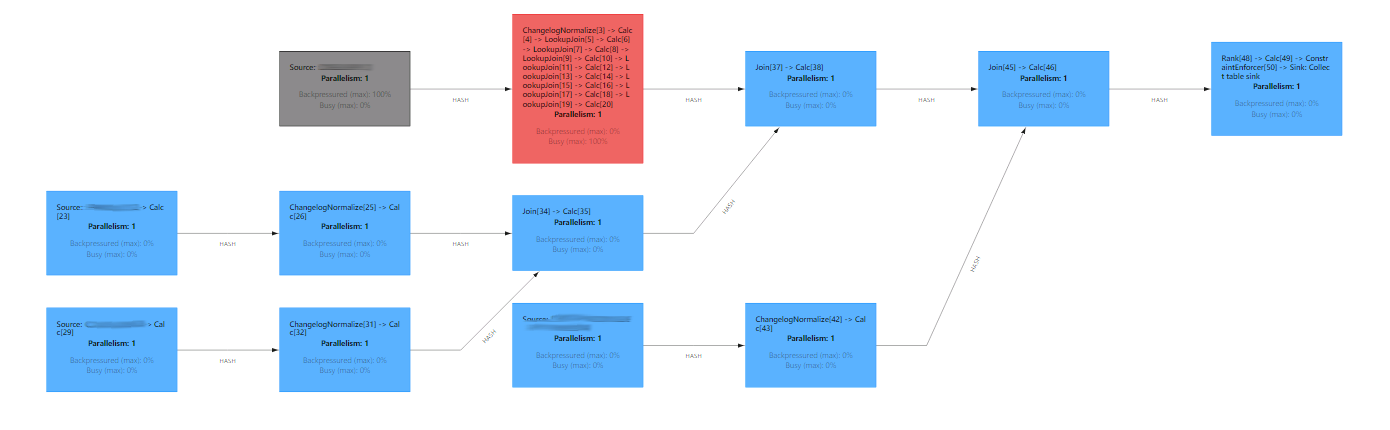
Results
The job was stable, scalable, and performant. Lookup joins with caching (with a 1-minute expiration timeout after writing) worked well. Flink chained all lookups into one operator, executing everything in place without transferring data. As a side effect, data skew on joins with dictionaries disappeared.
Eight heavy joins were replaced by stateless operators. The job still had some heavy operators:
- ChangelogNormalize for TABLE_A
- Two regular joins, and
- Rank function at the end.
This number could have been reduced further, but the client didn't accept the solution involving external storage. There were two reasons behind this decision: the client didn’t want to overload the storage and didn’t want to make the Flink job dependent on an external service.
Step back - Temporal join
The client opted against using a lookup join solution. Another possibility is a temporal join, which only keeps the right side in state. Temporal join comes with some limitations:
- It requires well-defined watermarks/data alignment.
- It cannot be used for one-to-many relations.
- It requires a primary key defined on the right side table for deduplication, which will be used for the join condition. Alternatively, it can be used with a temporal view with a redefined key, which supports only datastream, not changelog.
Thankfully, I was able to meet these conditions. The CDC data contains audit data and can be used for data alignment, and the join relation is one-to-one in my case.
Due to data skew, I had to perform some preprocessing before joining dictionaries with the main table. I called this method a pseudo-broadcast join and described it here.
That technique operates on a temporal view, which can only be built on an append-only stream. Due to this limitation, I had to convert the changelog from CDC events beforehand. This can be achieved in PyFlink, exposing the datastream back to Flink SQL as a view. Sample code is provided in the listing below.
Note that the code skips DELETE events, which may not always be appropriate.
# PyFlink 1.16.1
from pyflink.table import Row, Schema
from pyflink.table.types import RowKind
from pyflink.common.typeinfo import RowTypeInfo, Types
from pyflink.datastream import FlatMapFunction
class AppendOnlyConverter(FlatMapFunction):
def flat_map(self, row: Row):
# ignore DELETE and UPDATE_BEFORE
if row.get_row_kind() in (RowKind.INSERT, RowKind.UPDATE_AFTER):
yield Row(op_type=RowKind.INSERT, **row.as_dict())
# read from table
source_table = table_env.sql_query(f"SELECT * FROM {table_name}")
# table to stream
source_stream = table_env.to_changelog_stream(source_table)
output_type = Types.ROW_NAMED(fields, types) # the same as input
output_schema = Schema.new_builder() \
.column("ID", "BIGINT NOT NULL") \
# the other columns, may be only a subset of input
.watermark("LAST_UPDATE_DATE", "LAST_UPDATE_DATE - INTERVAL '5' SECONDS") \
.build()
# converting changelog to append-only stream
output_stream = source_stream.flat_map(AppendOnlyConverter(), output_type=output_type)
# exposing datastream as view back to Flink SQL
output_table = table_env.from_data_stream(output_stream, output_schema)
table_env.create_temporary_view(output_table_name, output_table)
After implementing these modifications, my job resembles the diagram below. It comprises 11 temporal joins in sequence, with the main table highlighted in yellow.
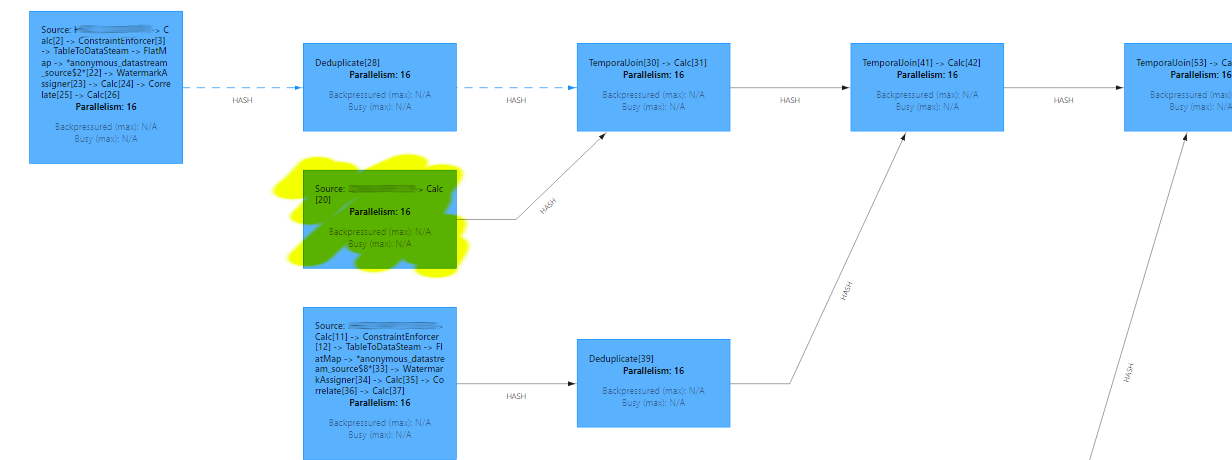
The deduplicate operator is a component of the temporal view responsible for tracking row updates. Despite utilizing state, it remains small for dictionaries.
I switched the connector from upsert-kafka to kafka for TABLE_A. As a result, Flink created a datastream instead of a changelog without heavy ChangelogNormalize. I could do this because DELETE events weren’t generated for TABLE_A and deduplication is not required for the left side table in temporal join.
Note that the pipeline requires sorting to prevent race conditions. Initially, I accomplished this using the Flink Rank function, but I opted to delegate that responsibility to the warehouse.
An alternative solution to reducing rank state involves utilizing operator-level state TTL parameter (released in Flink 1.18). This parameter defines for how long the state of a key is retained without being updated before it is removed. Instead of retaining the entire state to resolve race conditions, only the most recent values need to be kept.
Results
The job is stable. There are no heavy operators, and the checkpoint is created within almost constant time (a few seconds). The total checkpoint size is below 4GB! This is approximately 200 times smaller than the estimated state size for the same job with regular joins, which wasn't even able to process the entire dataset.
Summary
When it comes to state size, the lookup joins rules. Chained joins in place with cache are much more performant than temporal joins in-row, which are still much more state-efficient than regular joins. Processing a changelog instead of an append-only stream incurs a cost, which is not always necessary. Moreover, SQL queries, even if semantically equivalent, may result in different query plans and job’s DAG created by Flink SQL, significantly impacting performance.
In this blog post, I shared some hints and tricks on how to minimize the job state, starting from detecting the heaviest operators and replacing them with more suitable alternatives. While it isn't always possible to do this, in most cases, it could be achieved. As a result, your job will be stable, start up quickly after failure, and consume fewer resources. You will also notice a performance boost. Checkpointing is a vital part of a Flink job and cannot be neglected.
Ready to optimize your Flink SQL jobs for better performance and reliability? Sign up for a free consultation with our experts today, and subscribe to our newsletter for the latest tips and best practices.