Tutorial
Flink SQL - Changelog and Races
Managing data efficiently and accurately is a significant challenge in the ever-evolving landscape of stream processing. Apache Flink, a powerful…
Read moreIn the rapidly evolving field of artificial intelligence, large language models (LLMs) have emerged as transformative tools. They’ve gone from powering simple demos to becoming integral components of sophisticated enterprise applications. Nevertheless, as organizations seek to deploy these systems at scale, a new discipline has arisen: LLMOps. In a recent webinar, Marek Wiewiórka, Chief Data Architect at Getting Data | Part of Xebia, provided invaluable insights into this field, discussing how to transition from playground experiments to production-ready generative AI systems.
Watch the webinar on demand, and let’s dive into the highlights from the session.
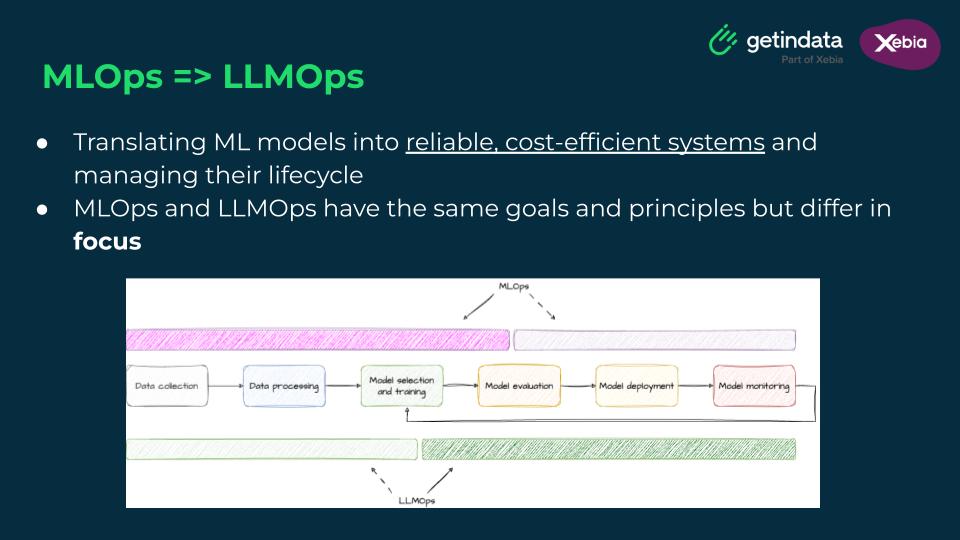
Many AI practitioners are familiar with MLOps, the operational backbone for deploying and managing machine learning models. But LLMOps, while sharing some similarities, diverges in key ways:
Marek outlined several challenges unique to deploying LLMs in enterprise contexts:
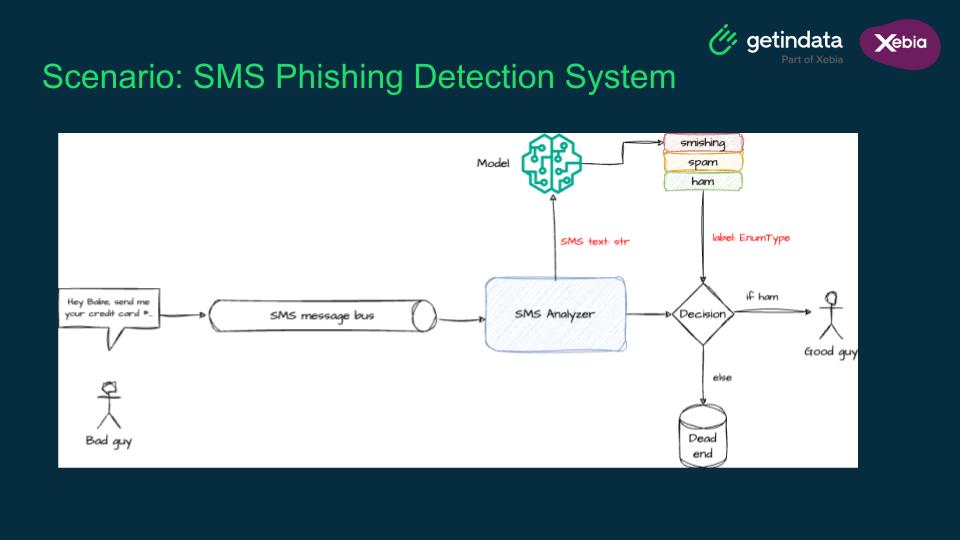
Marek shared an inspiring example of transitioning from a simple demo to a production-ready system. The project involved building an SMS phishing detection system powered by LLMs. Here’s a summary of the process:
The webinar showcased practical tools and frameworks for implementing LLMOps, including:
These tools enable developers to automate traditionally manual tasks, making large-scale deployments more feasible and efficient.
LLMOps is not just a scaled-up version of MLOps - it’s a new paradigm tailored for the unique demands of generative AI. As enterprises embrace these models, they must also grapple with governance, security and cost-efficiency. Marek emphasized that building production-grade systems demands automation, robust evaluation processes and a willingness to adapt to the fast-paced evolution of AI.
As LLMs continue to transform industries, LLMOps is becoming an indispensable discipline for AI practitioners. Whether you're building the next-gen co-pilot or a secure SMS filter, the principles outlined in this webinar can guide your journey from experimentation to enterprise-scale deployment.
For more details, check out the GitHub Repository: https://github.com/mwiewior/llmops-webinar with a demo code, or watch the full webinar recording.
Let’s turn ideas into action! 🚀
Managing data efficiently and accurately is a significant challenge in the ever-evolving landscape of stream processing. Apache Flink, a powerful…
Read moreStaying ahead in the ever-evolving world of data and analytics means accessing the right insights and tools. On our platform, we’re committed to…
Read moreInterested in joining the data analytics world? Not sure where to start? Are more and more questions popping into your head? I’ve been there myself…
Read moreIn this blogpost series, we share takeaways from selected topics presented during the Big Data Tech Warsaw Summit ‘24. In the first part, which you…
Read moreIn today's data-driven world, maintaining the quality and integrity of your data is paramount. Ensuring that organizations' datasets are accurate…
Read moreApache Sedona is a distributed system which gives you the possibility to load, process, transform and analyze huge amounts of geospatial data across…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?