


Use-cases/Project
Integration tests of Spark applications
You just finished the Apache Spark-based application. You ran so many times, you just know the app works exactly as expected: it loads the input…
Read moreBig Data Technology Warsaw Summit 2021 is fast approaching. Please save the date - February 25th, 2021. This time the conference will be organized as an online interactive event. This makes it easier for everyone to speak and attend because there is no need to travel to Warsaw.
As the Call for Presentation (CfP) is still open, we’d like to encourage you to submit your proposals. To shed some light on how submissions are rated and selected, we describe our evaluation process in this blog post.
The deadline for the CfP is October 10th, 2020 and the submission page is here.
First and foremost, we aim for presentations about case studies, technologies that solve real-world problems, best practices and lessons learned. We reject submissions containing outright sales pitches and commercial presentations.

In each submission we evaluate a presentation value, uniqueness of its subject, alignment with conference core and also speaker’s professional achievements.
You can check the agenda of the last edition of the conference and notice that many presentations score very high in each of these 4 criteria. Among top-rated presentations during the CfP process in 2019 were, for example, “Building Recommendation Platform for ESPN+ and Disney+. Lessons Learned”, “Presto @Zalando: A cloud journey for Europe’s leading online retailer”, “Reliability in ML - how to manage changes in data science projects?” or “Omnichannel Personalization as an example of creating data ROI - from separate use cases to operational complete data ecosystem”.
There are several tracks at the conference and all of the criteria above apply to all conference tracks excluding one.
This year, as an experiment, we decided to launch a new track called “Academia, the incubating projects, and POCs”. Presentations submitted to this track will be scored in a standard way against the Alignment, Uniqueness and Speaker criteria, but we will not expect that submissions describe production use-cases or battle-proven technologies that work at large scale. However, we assume that listening to these presentations will still bring value to the audience by putting some technologies into their radars or introducing new techniques or use-cases that might be popular in the future.
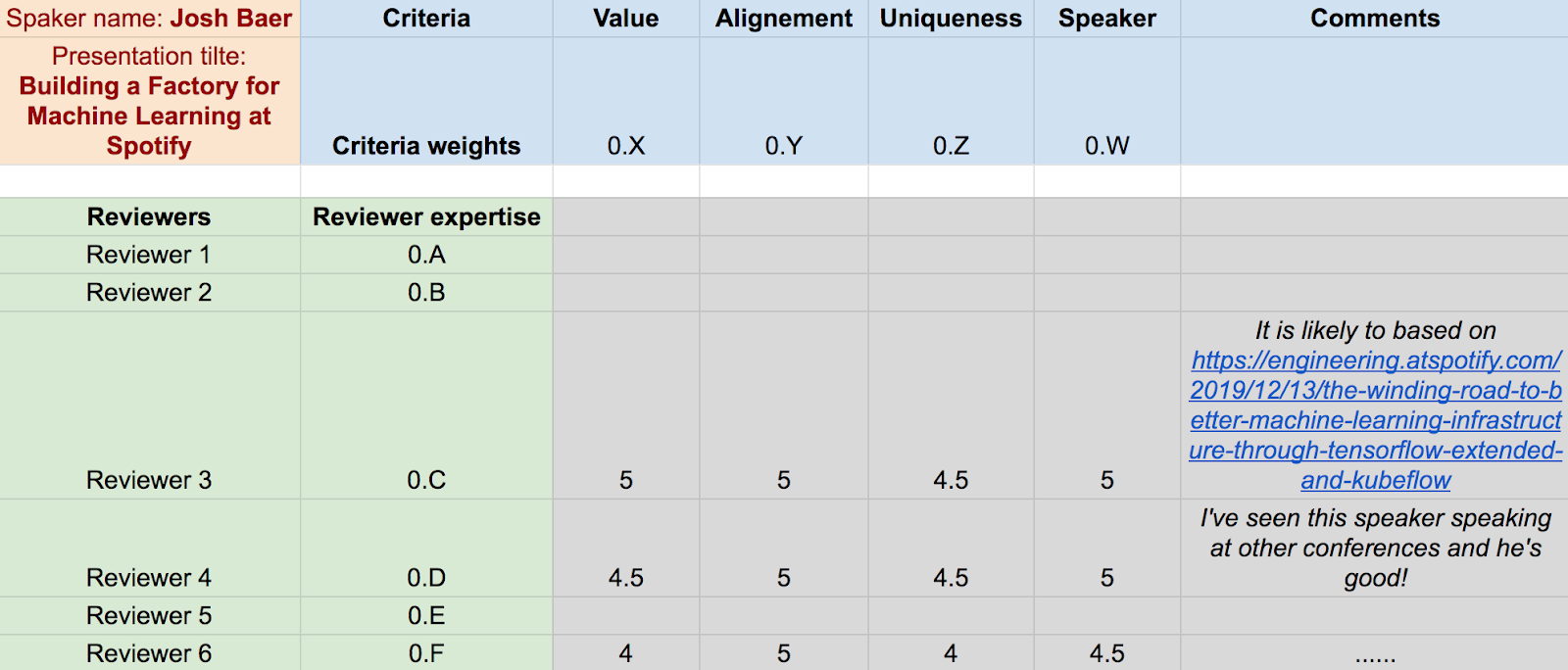
Our CfP committee is quite large and consists of experts who have practical experience in the data-related field and work at top data-driven companies. Each reviewer has her/his own area of expertise. Typically each reviewer rates presentations in multiple tracks, and she/he can specify the importance (weight) of her/his rating in each particular track (from 0.0 meaning no expertise, to 1.0 meaning a lot of expertise). For example, a reviewer who is a senior data engineer specializing in building real-time streaming solutions can rate two tracks (i.e. data engineering and real-time streaming analytics) and give them slightly different weights.
To minimize the risk of bad decisions, multiple reviewers rate each submission (4 reviewers on average) and discuss them. Typically, we add comments next to the ratings so that we share our findings, feedback, concerns across the committee. We assume it’s fine that someone can change her/his vote after hearing feedback from others. We want the CfP process to be a discussion where the CfP members collaborate together to select the best submissions.
In the first round, each committee member rates presentations in her/his track(s) in four categories and provides additional comments. Here is an example:
We calculate a score for each submission based on the ratings, criteria weights and reviewers expertise.
Then for each track, we build a quite large list of good-rated presentations. During this process, we have several discussions and iterations based on provided comments and other findings so that we can review each presentation as carefully as possible and re-review them again if needed.
It happens that we have multiple submissions from the same speaker or from the same company. Often all of them get high scores because they are practical, unique, and aligned to the conference core. However, to build a more diverse agenda, we must avoid multiple presentations from the same company or about the same technology or about the same use-case. For example, two years ago we rejected very good submissions about Apache Flink to avoid too many talks about Flink in the real-time streaming analytics track and accepted a bit lower-rated presentation about Apache Apex to cover a more diverse set of stream processing technologies. A year ago, we had one speaker who sent us three very well-rated submissions, and we had to accept only one of them, even though two other ones scored better than other presentations that we accepted. Also two years ago, we had three submissions about automotive and self-driving cars and we had to reject at least one of them, even though all of them looked good.
Also, a given submission might fit multiple tracks, so in this round we also check if some submissions can be moved across the tracks in case a particular track is too crowded.
As you see, our process is not automated and it requires a lot of brainstorming to build the agenda.
In this round, we divide the short-list into two parts - the submissions that we accept now, and the waiting list.
It turns out that each year a few speakers have to cancel their presentations a few days or weeks before the conference for various reasons. To find a proper replacement we ask speakers from the waiting list first if they can still speak at the conference.
During the conference we ask the audience to score each attended presentation so that we collect the feedback about its quality. Thanks to that we can also check if the presentations accepted by the CfP committee were enjoyed by the audience.
Last time, 18 out of 33 presentations given at the conference received a very good score from the audience (average of at least 4.0 in the 1-5 scale). Let’s call them well-rated presentations. 2 out of 33 presentations received a quite bad score from the audience (lower than 3.0 on average). Let’s call them badly-rated presentations. Here are some stats:
In other words, if the CfP committee accepts a submission it will be most likely enjoyed by the audience, or at least it will not disappoint the audience. We are quite happy about these numbers, but of course we still see the room for improving our process.
Here are some stats that come from the CfP process that took place a year ago, in 2019, before the last edition of the conference.
As you see, it was extremely difficult to select the best presentations and at the same time reject many very good ones.
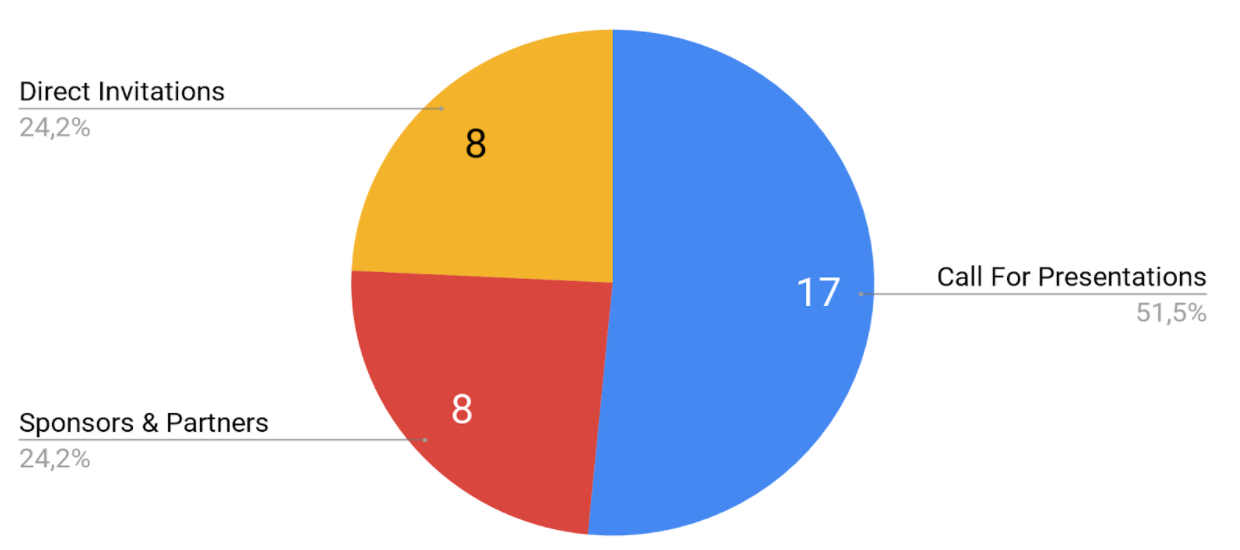
During the last edition of the conference, over half of the presentations came from CfP. This was intentional because we want the conference to be open for the community, make sure that everyone who has a good story to share can speak at the conference.
8 presentations were given by personally invited speakers. Those are always experts that we identified in the community, verified their experience by watching some of the presentations or reading their blog posts. Also, 8 presentations were delivered by our sponsors and partners.
We achieved good coverage of technologies including battle-proven and state-of-the-art technologies such as Kafka, Flink, Presto, Kubernetes, or Google Cloud as well as new cool kids on the block like Hudi or Amundsen or rising stars like Snowflake.
How were the above technologies actually presented at the conference? We encourage you to read our blog post about top 5 biggest ideas to hear during the edition of Big Data Technology Warsaw Summit 2021.
Half of the presentations were about infrastructure, platforms, architecture and engineering efforts to make big data projects successful. Speakers talked about how the above technologies were used by them as building blocks to build their data analytics platforms for real-time and batch processing, or for deploying large-scale ML projects. They talked about on-premise, the public cloud or about migration to the cloud.
The other half of the presentations will be about actually using the big data platforms and the data to implement data-driven algorithms, get insights and solve business use-cases such as recommendation systems, omnichannel personalisation, credit risk, insurance etc.
It is a quite long blog post, but hopefully we explained how we evaluate submissions for Big Data Technology Warsaw Summit 2021 and why the process looks this way.
We’d like to encourage you to submit your proposal. Remember that the deadline for the CfP is October 10th, 2020 and the submission page is here.
You just finished the Apache Spark-based application. You ran so many times, you just know the app works exactly as expected: it loads the input…
Read moreWelcome to the next instalment of the “Power of Big Data” series. The entire series aims to make readers aware of how much Big Data is needed and how…
Read moreThe partnership empowers both to meet the growing global demand Xebia, the company at the forefront of digital transformation, today proudly announced…
Read moreDiscovering anomalies with remarkable accuracy, our deployed model successfully identified 90% true anomalies within a 2-months evaluation period…
Read moreFeature Stores are becoming increasingly popular tools in the machine learning environment, serving to manage and share the features needed to build…
Read moreReal-time analytics are all processes of collecting, transforming, enriching, cleaning and analyzing data to provide immediate insights and actionable…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?