Use-cases/Project
Integration tests of Spark applications
You just finished the Apache Spark-based application. You ran so many times, you just know the app works exactly as expected: it loads the input…
Read moreIn this blog post, I would like to cover the hidden possibilities of dynamic SQL processing using the current Flink implementation. I will showcase a custom component based on KeyedBroadcastProcessFunction, which can take the event source and the SQL source as input, and return the result of each sent query. This makes it possible to run multiple Flink SQL queries in a dynamic, user-oriented way.
See the dynamic SQL processing demo here. Its implementation is based on a demo from this great blog series by Alexander Fedulov. This blog series showcases patterns of dynamic data partitioning and dynamic updates of application logic with window processing, using the rules specified in JSON configuration files. Fedulov’s implementation of the dynamic process functions was also based on KeyedBroadcastProcessFunction, so it was also possible to reuse some of the code from that implementation. What's more , the web application created for the dynamic SQL processing demo is based on Fedulov’s demo web app, which was tailored to our needs. While the configuration possibilities defined in Fedulov’s demo are extensive, the generality of the solution presented below is greater, as it allows the execution of arbitrary SQLs dynamically, instead of the JSON template-based execution.
The following sections reveal the solution's concept and implementation details, showcase demo features and suggest the possible ways forward.
Let’s consider a scenario, in which an organization is interested in creating new data streams for analytics purposes, using Flink SQL to query the existing data streams. The team of analysts is able to quickly develop new streams with interesting insights, but experiences a bottleneck when deploying those streams to production. As changes to existing Flink jobs were made, they needed to be redeployed, causing possible downtime and adding complexity to the analytics team's process.
The presented solution aspires to remove the downtime by allowing the analytics team to run the developed queries at will, without the need for Flink job redeployment, and instantly get feedback from the insights discovered by new data streams.
The basic concept that makes the above possible is illustrated in the below diagram. The desired operator can take the event source and the source of SQL queries executed on the event source as input. The event source is assumed to be pre-keyed. The SQL stream is broadcasted to each of the physical partitions of the input. For each incoming broadcasted SQL event, the SQL query inside the event is executed. For each incoming source event, the SQL queries and their results are returned.

This dynamic SQL execution concept is something that Flink (as of v1.11.1) does not provide out-of-the-box, as it is currently not possible to run a new Flink SQL on an existing flow without job redeployment. The trick to make it work is to dynamically create new Flink instances inside the Flink process function - a “Flinkception”, if you will. This trick will be covered more extensively in the Implementation details section.
In order to access the demo contents, simply clone its repository:
git clone git@gitlab.com:<GitHub link>.gitThe detailed instructions on how to run a demo are located in README.md. However, in order to run a demo in a default setting, the following commands are enough:
docker build -t demo-webapp:latest -f webapp/webapp.Dockerfile webapp/
docker build -t demo-flink-job:latest -f flink-job/Dockerfile flink-job/
docker-compose -f docker-compose-local-job.yaml up
Once the above steps have been taken, head over to the location:5656 to see the React web application of the demo.
The demo allows interacting with a stream of randomly generated financial transactions with the following schema, again copied from this blog:
By default, there is one SQL rule already running at the start of the application. From now on, the following actions are available:
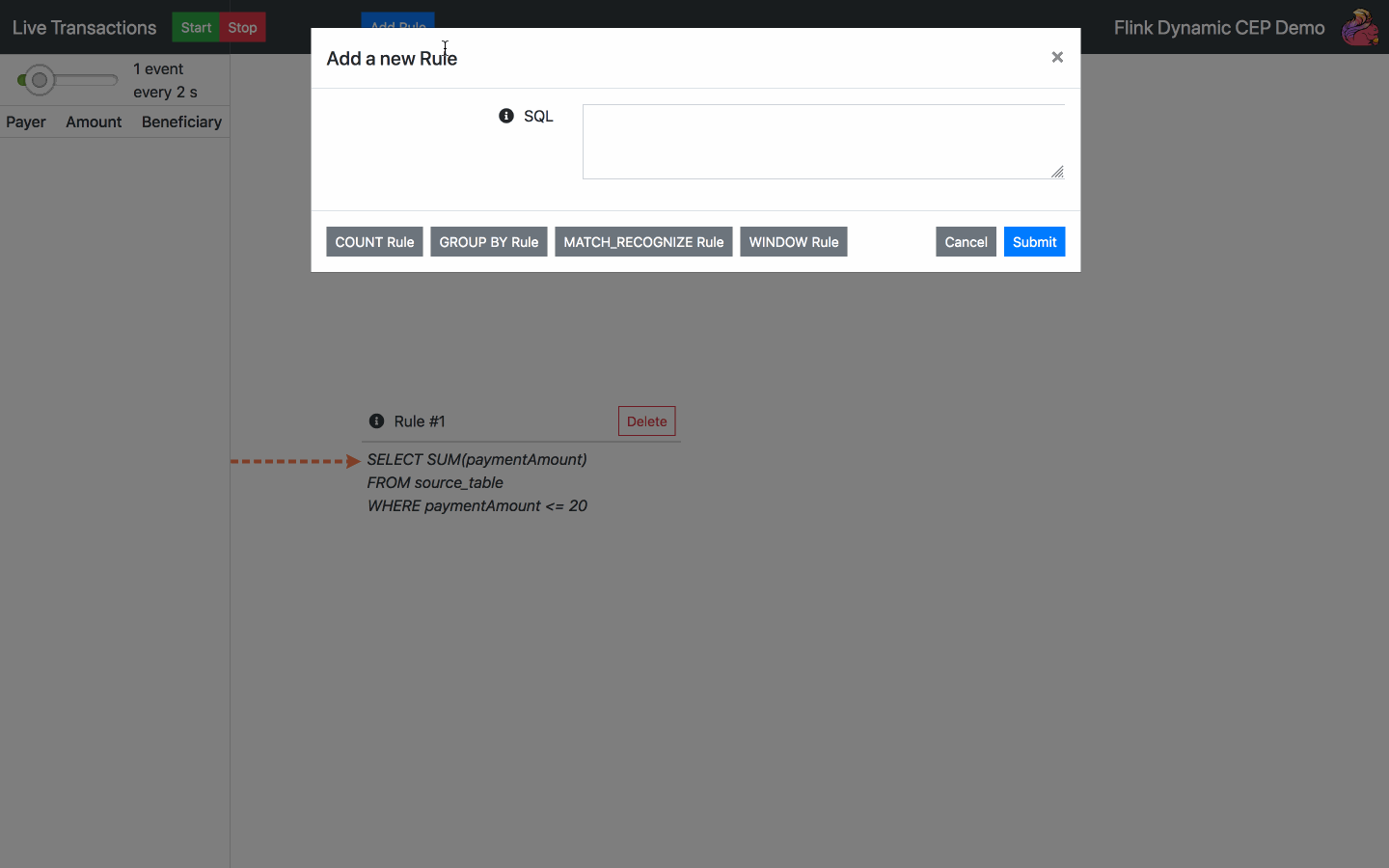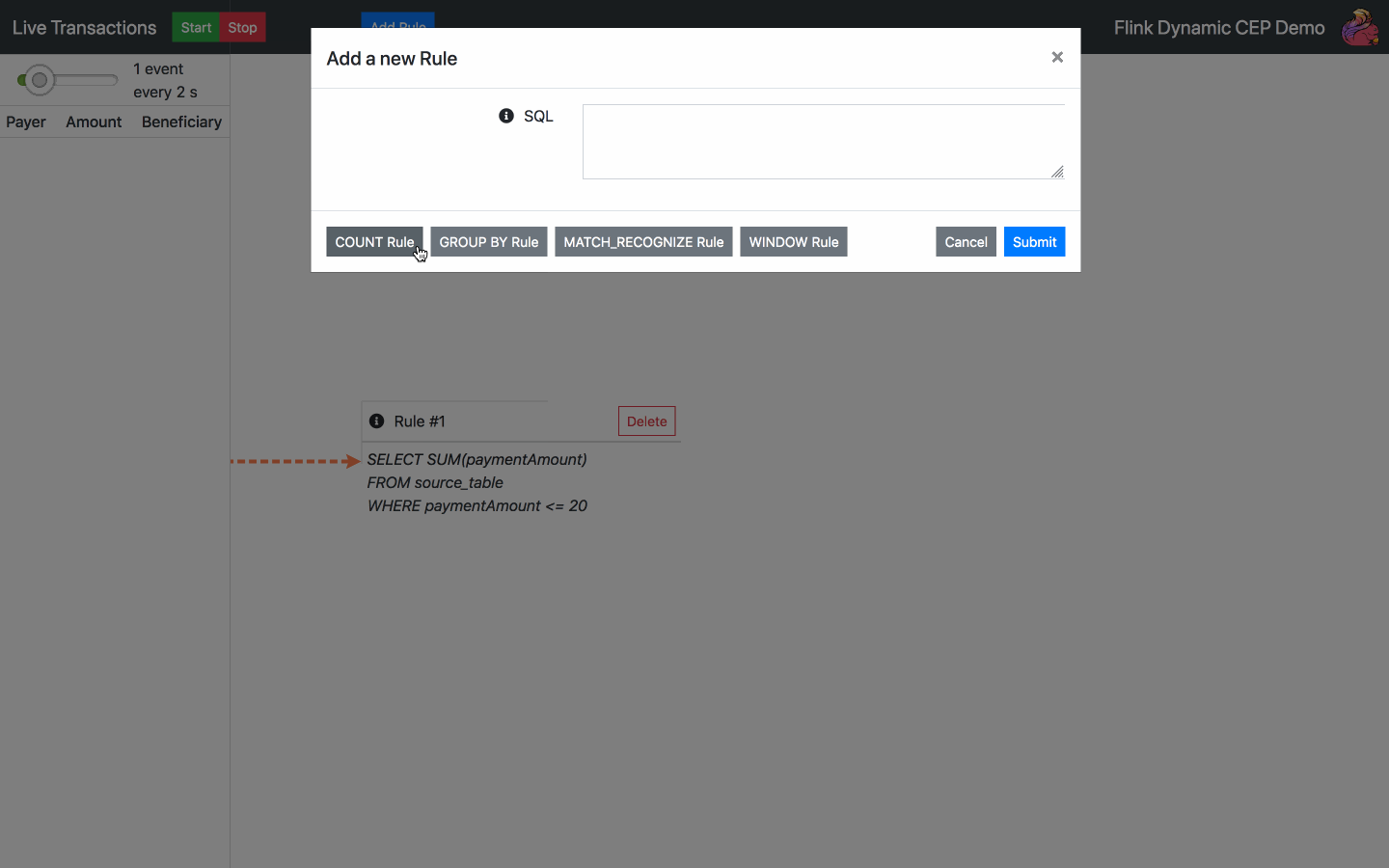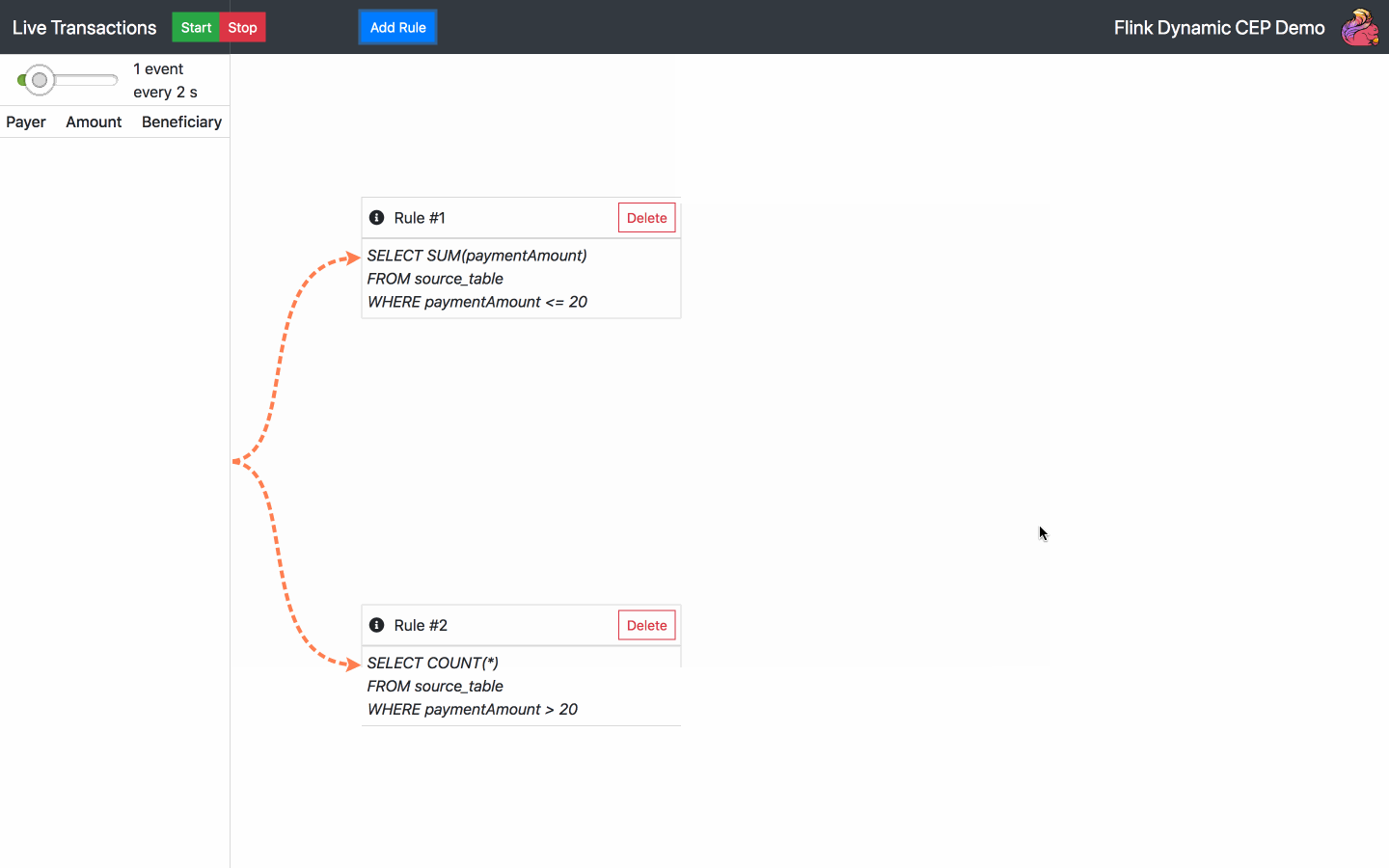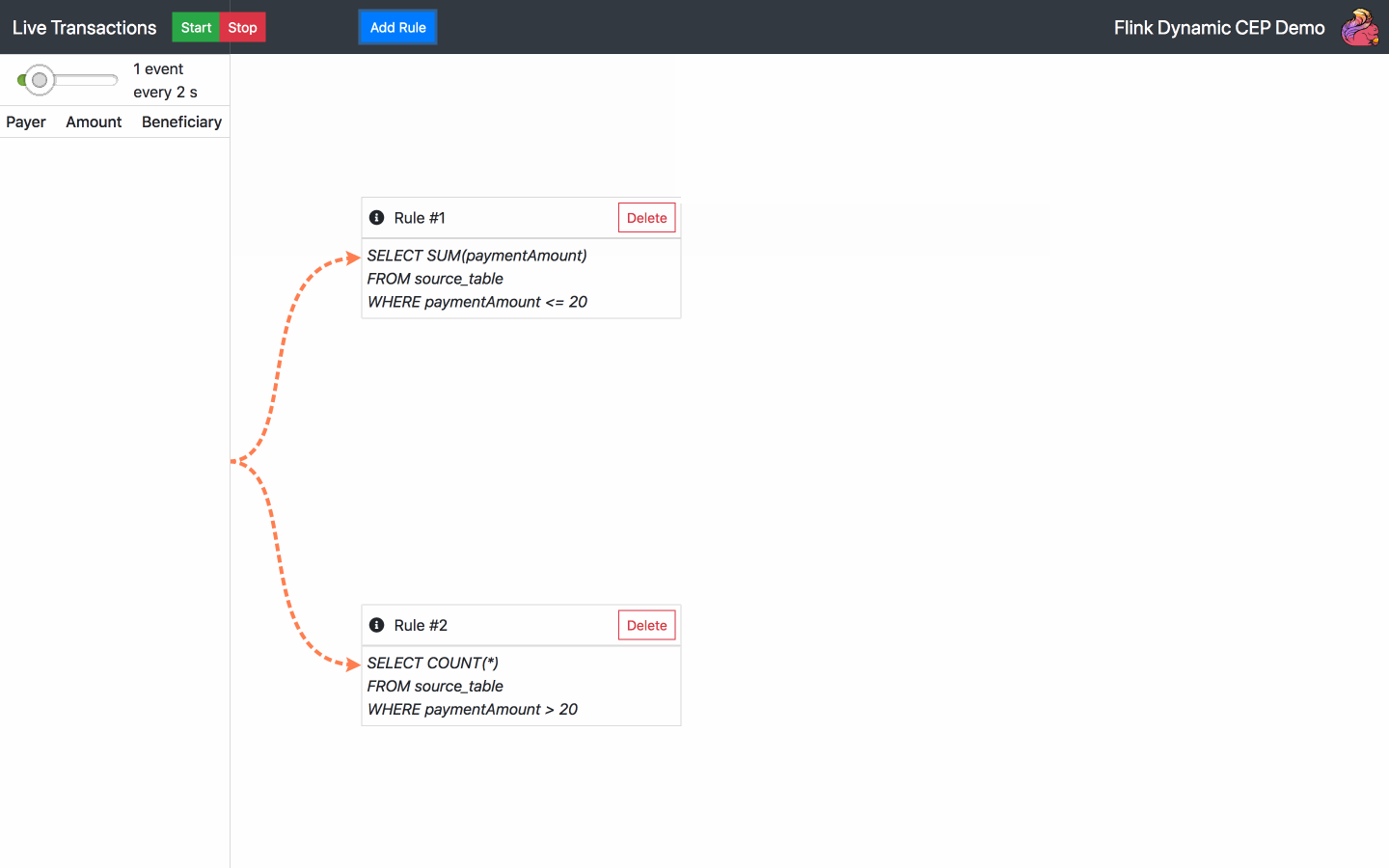
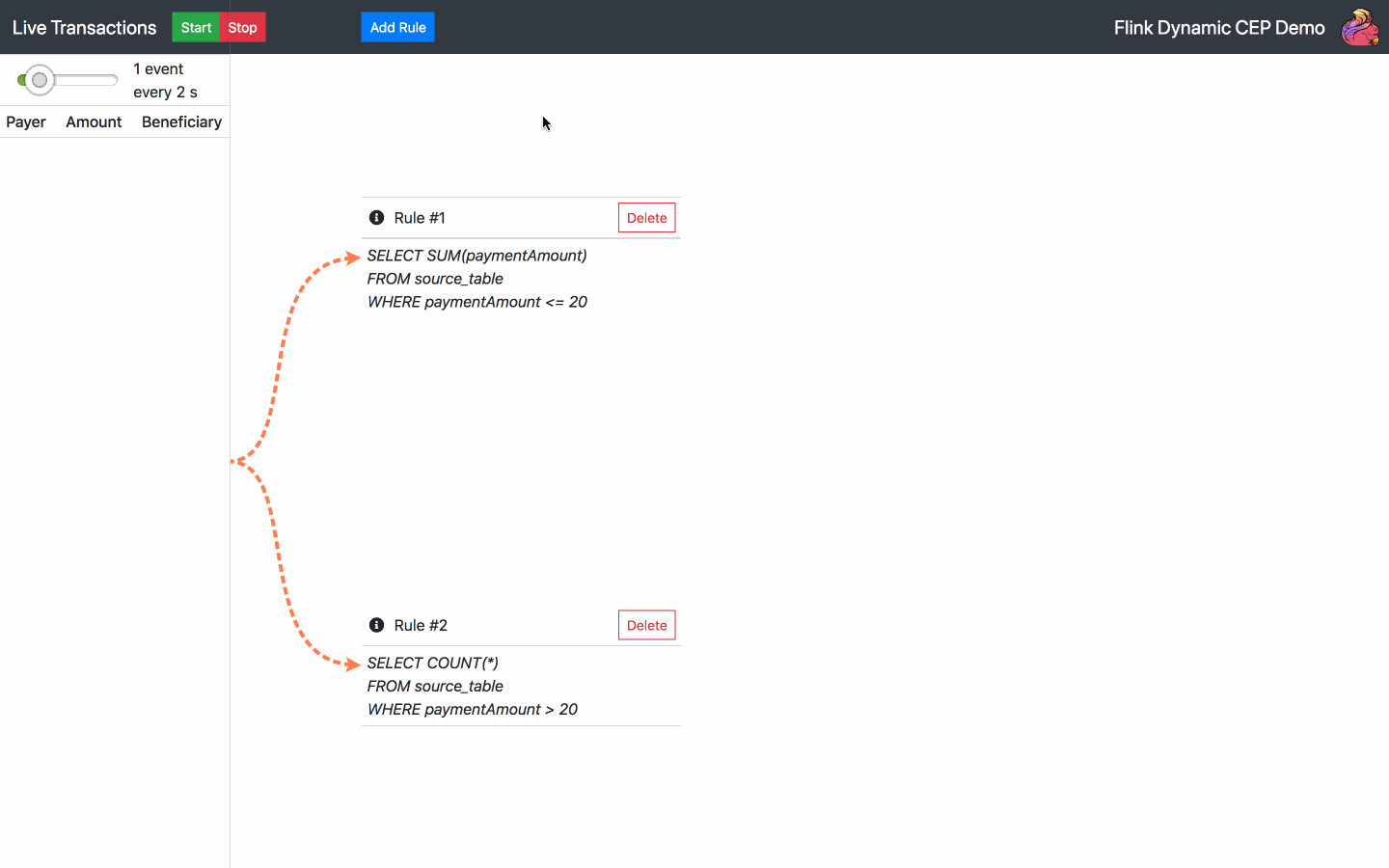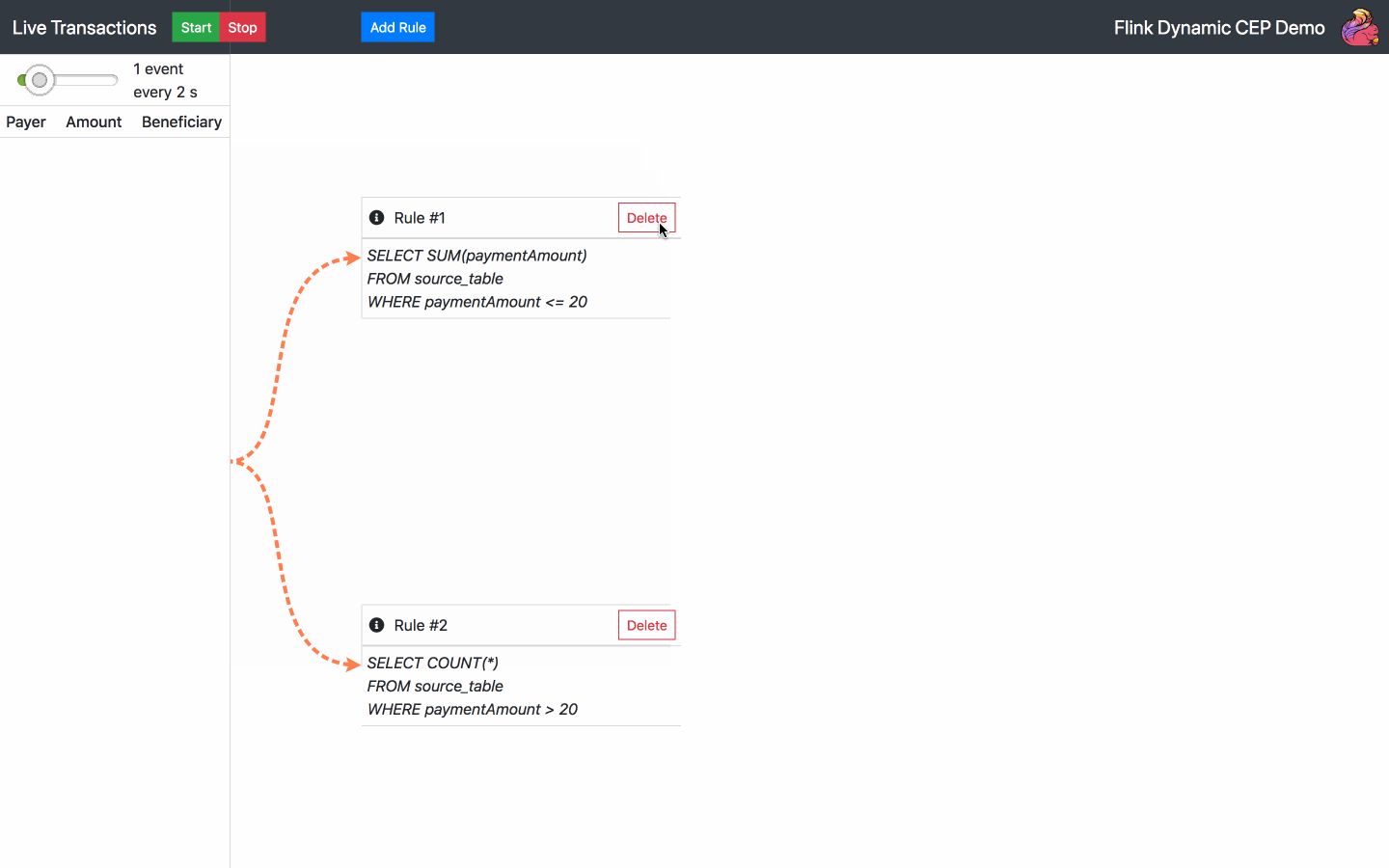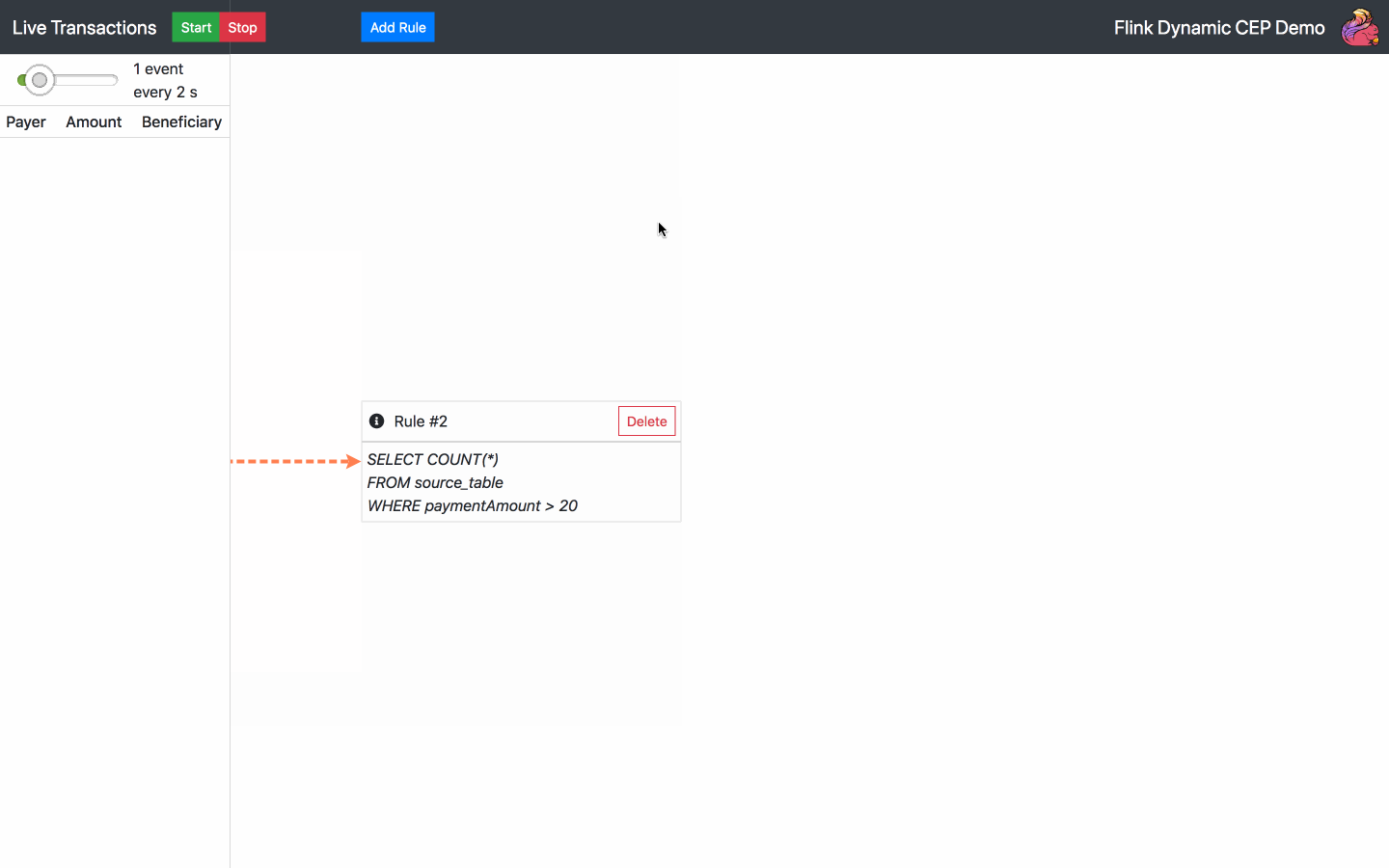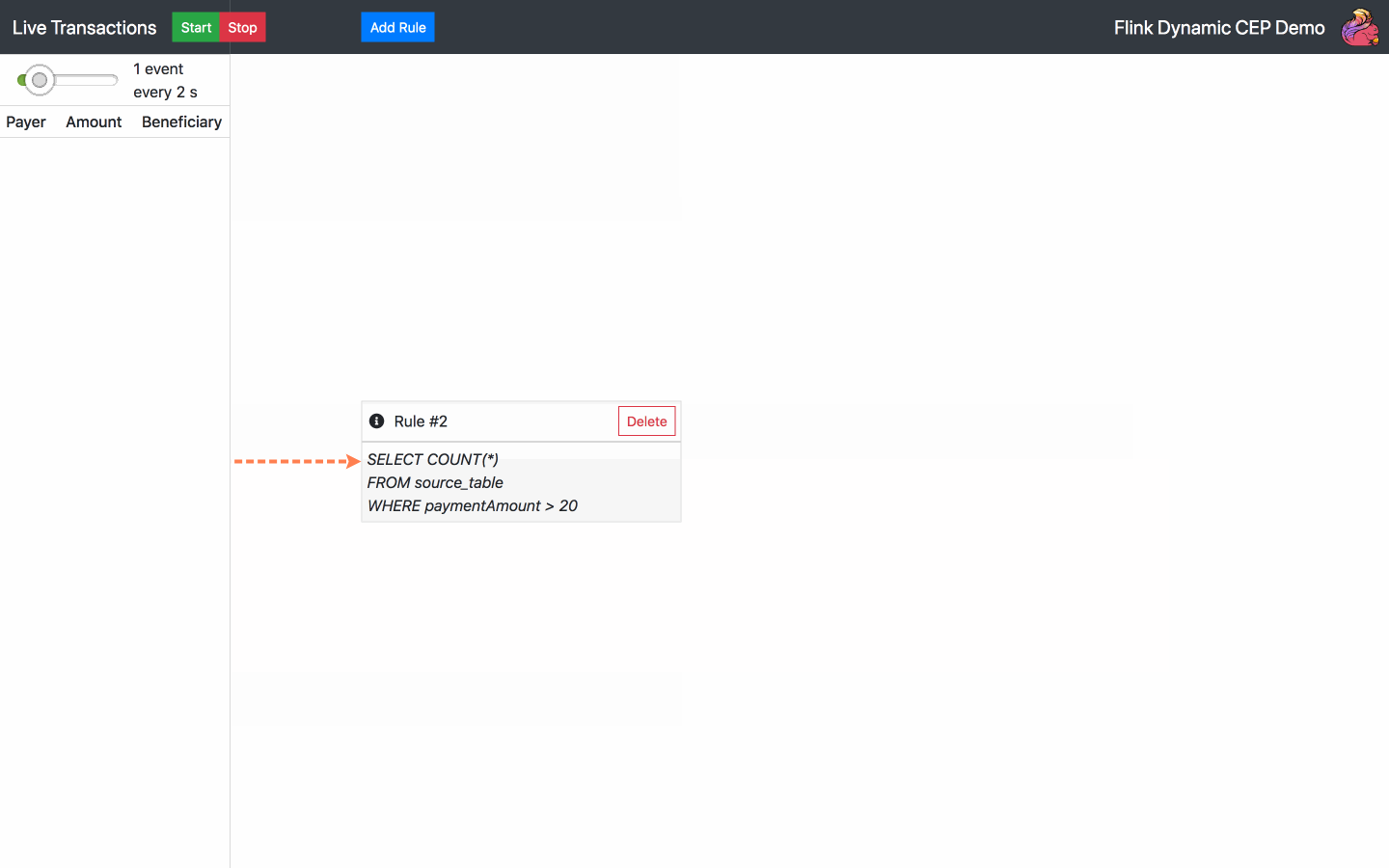
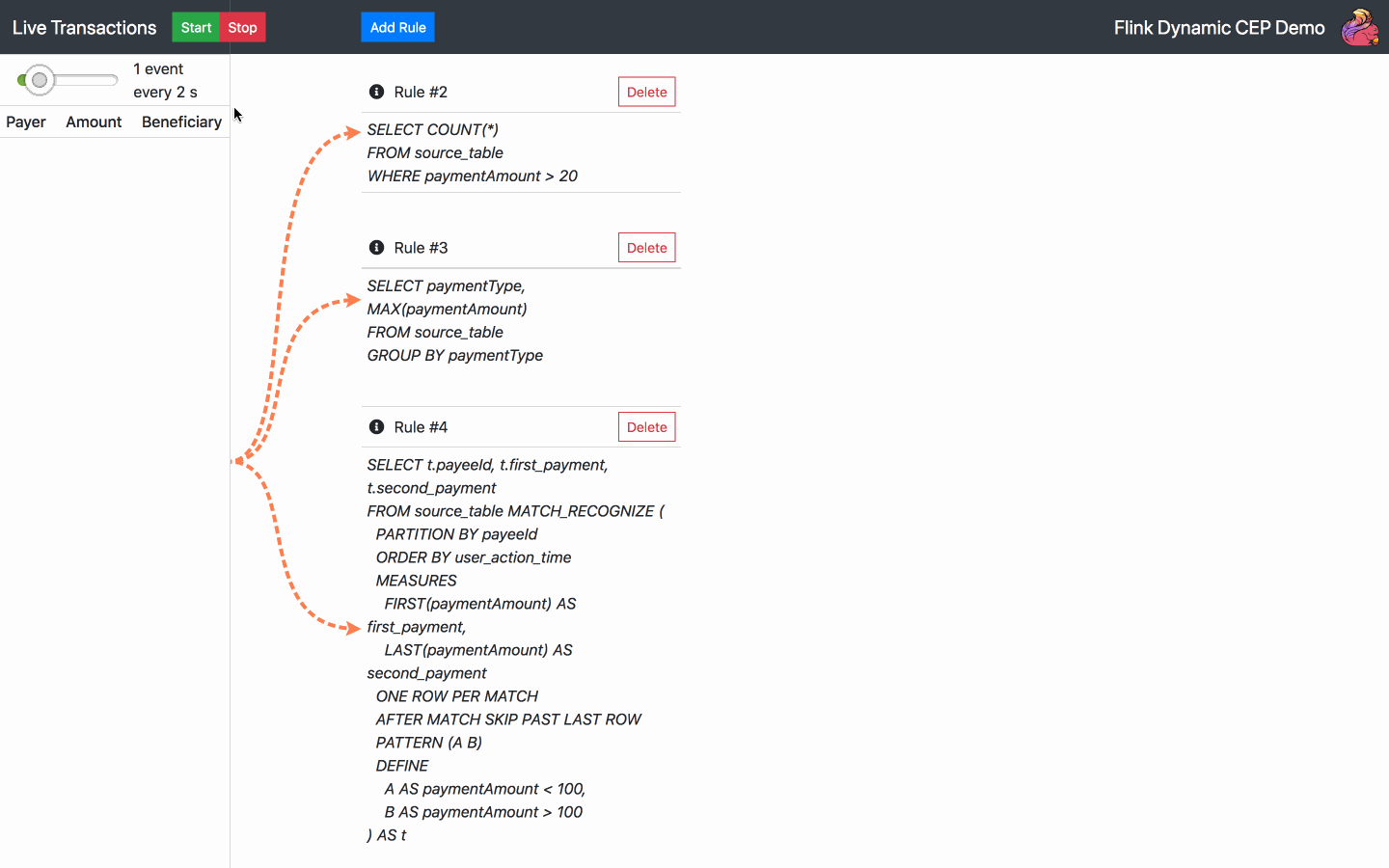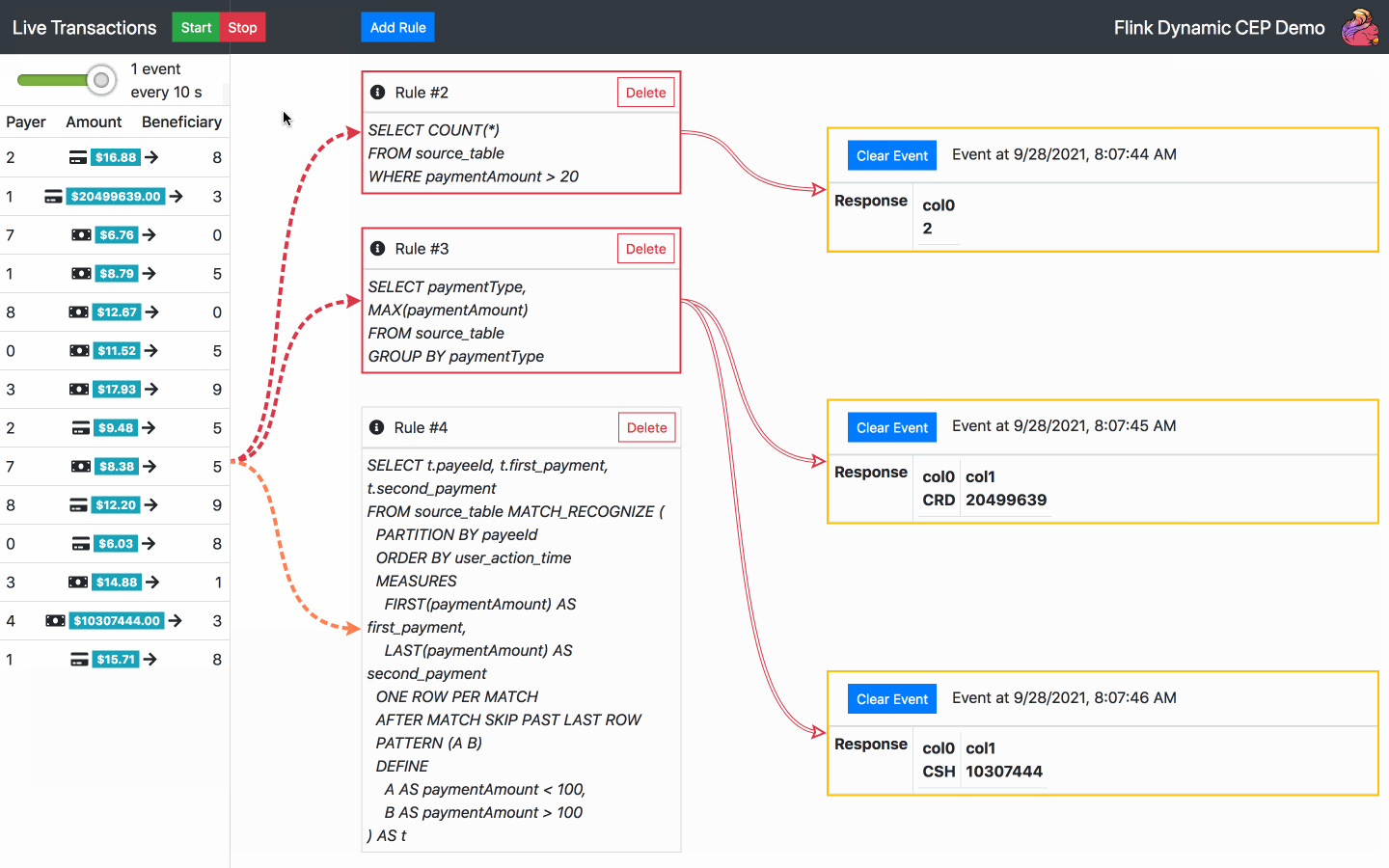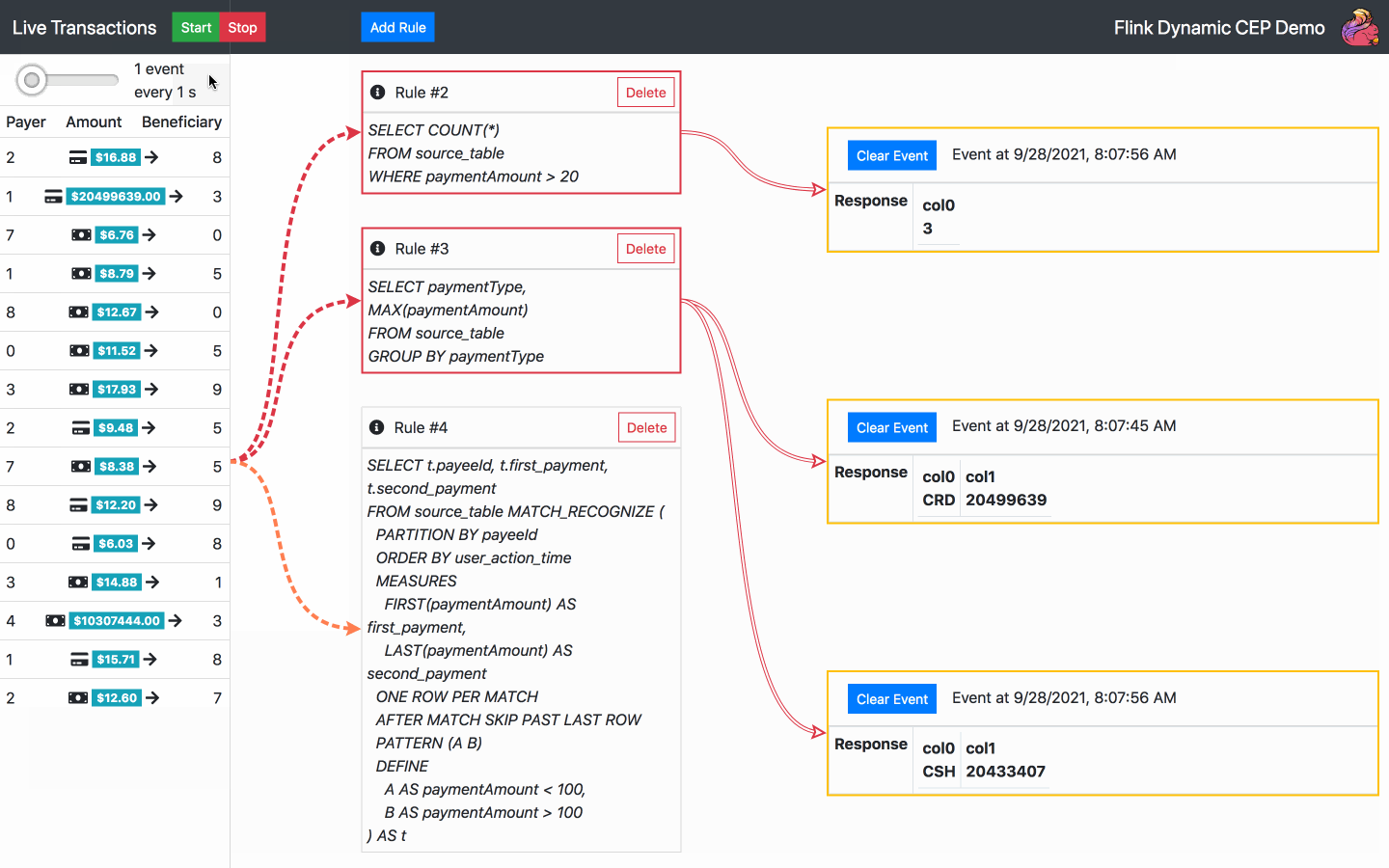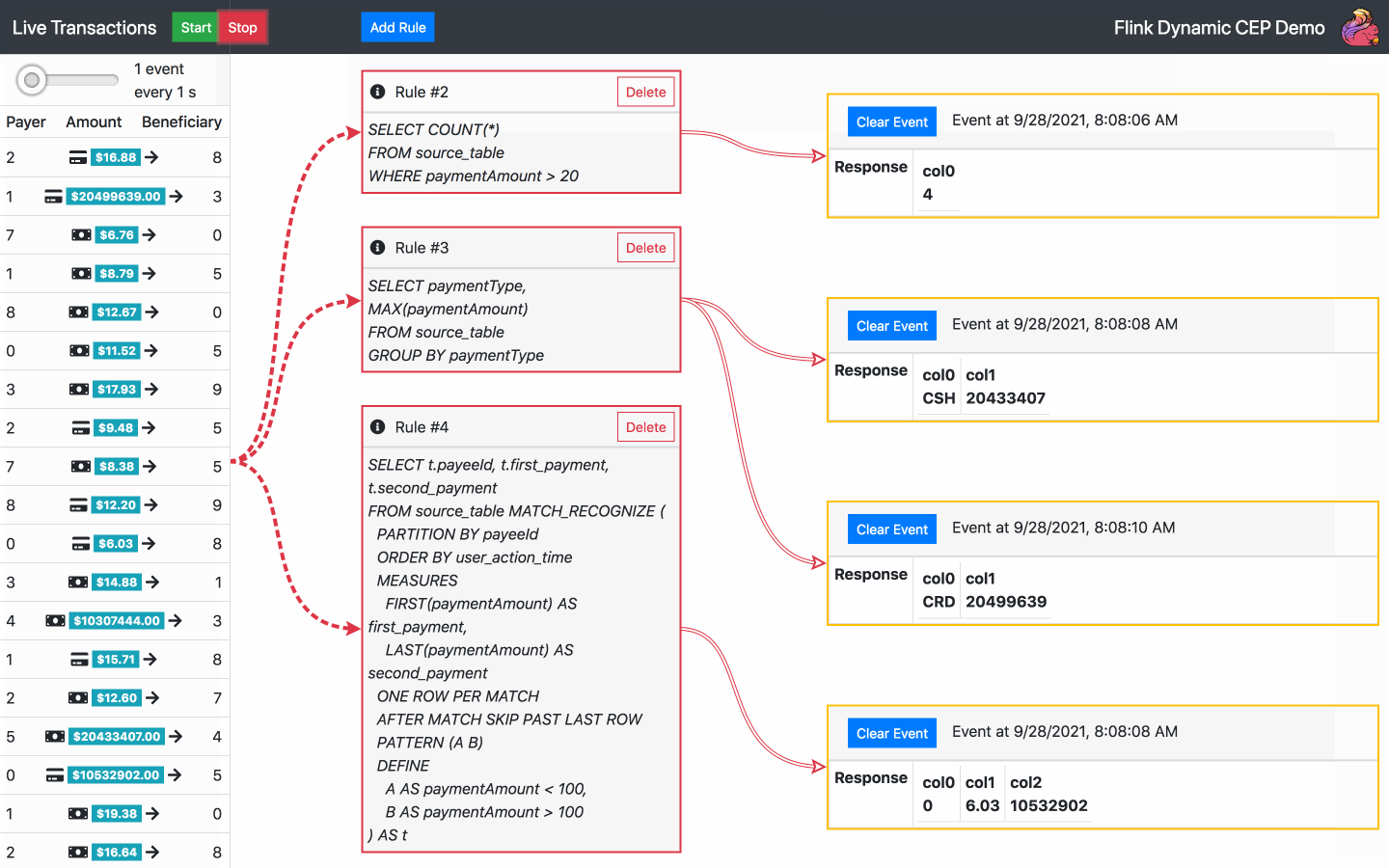
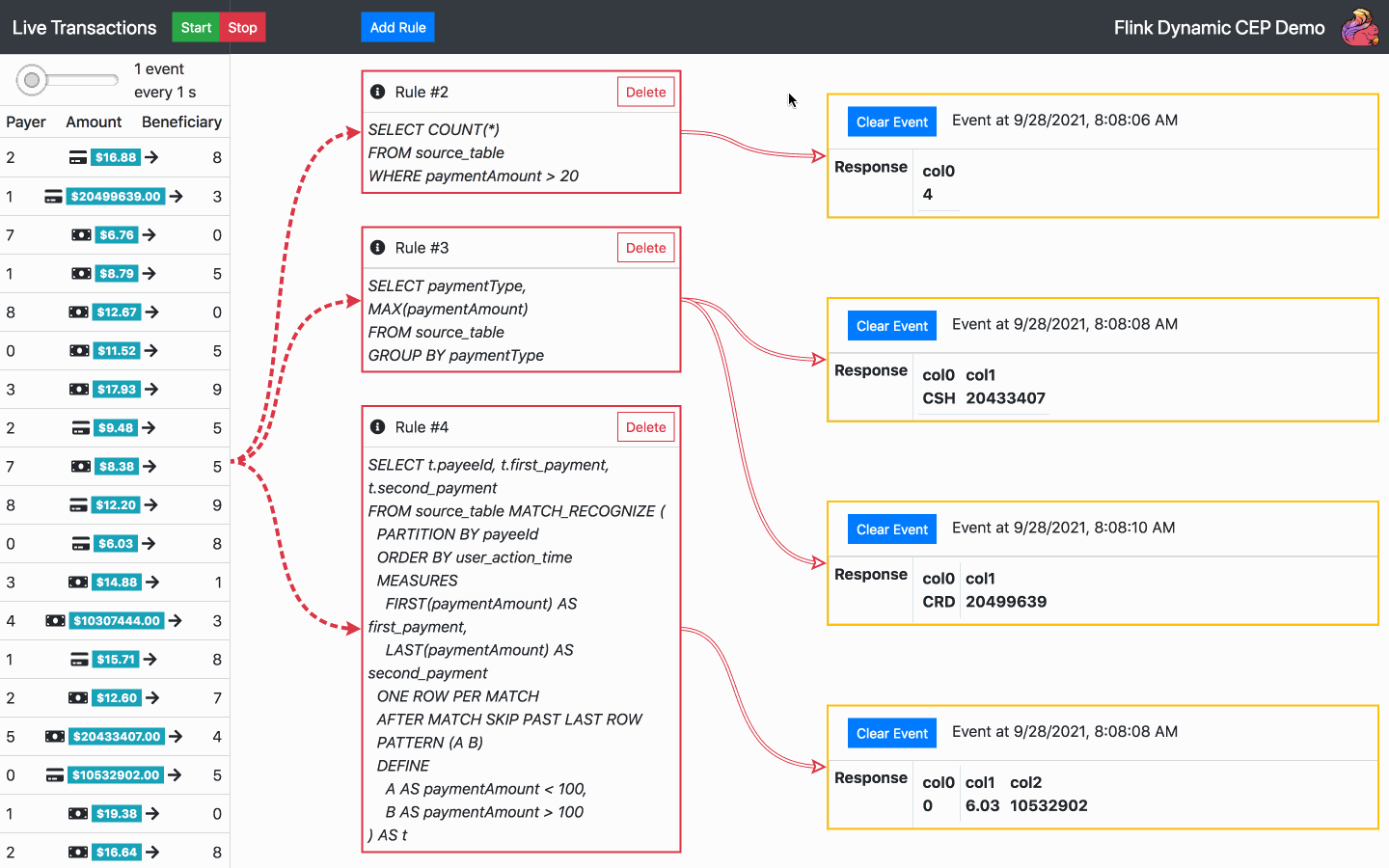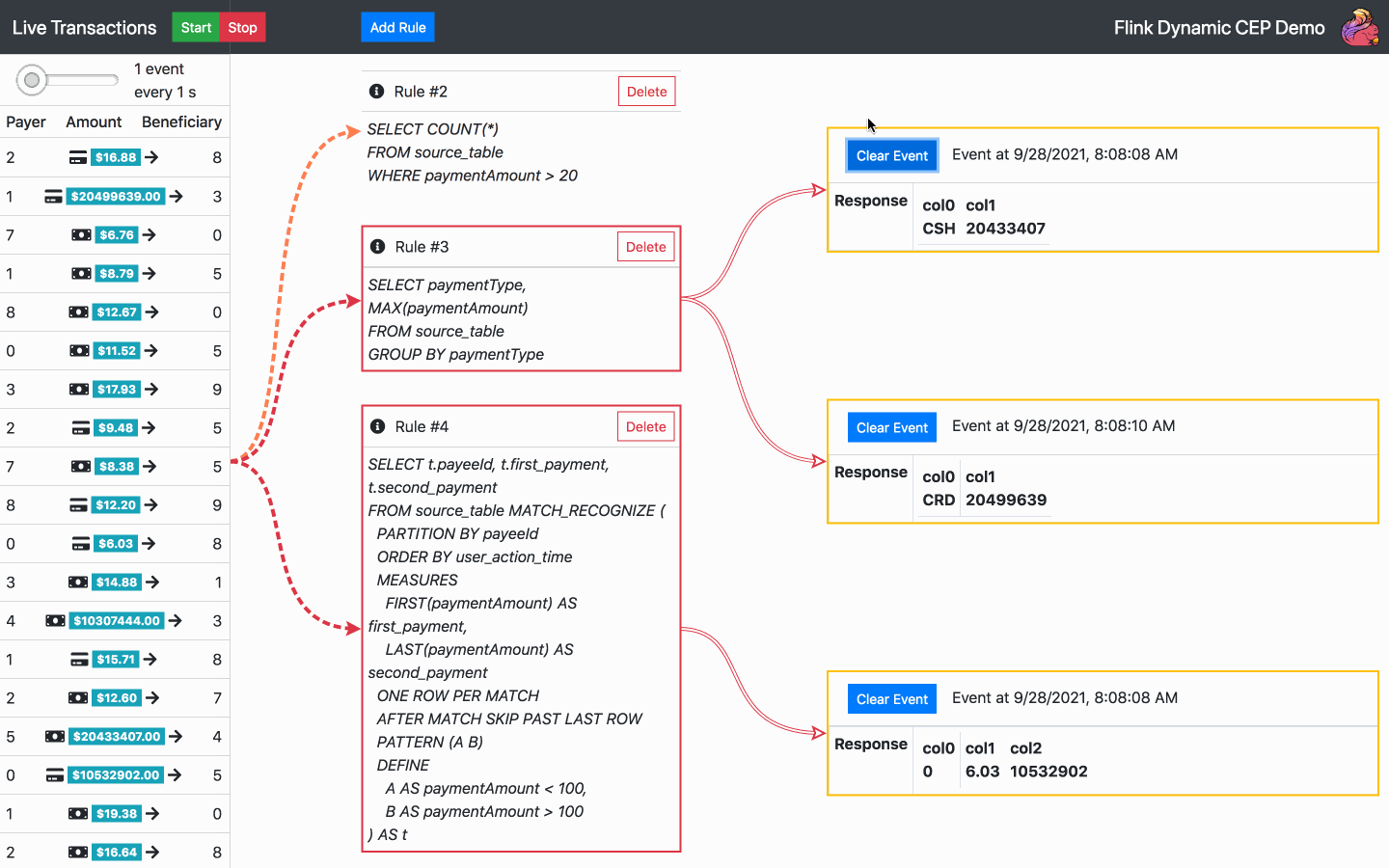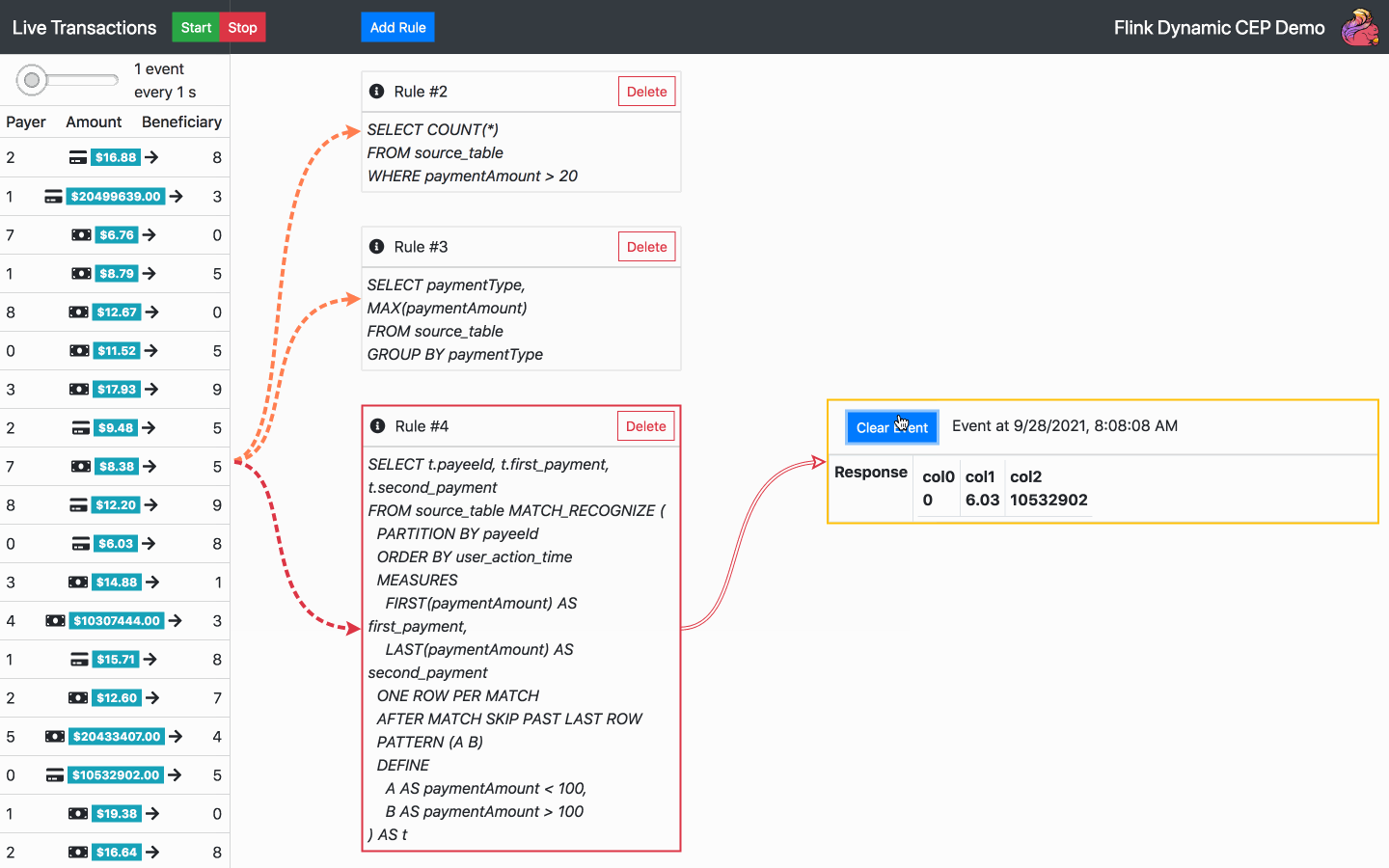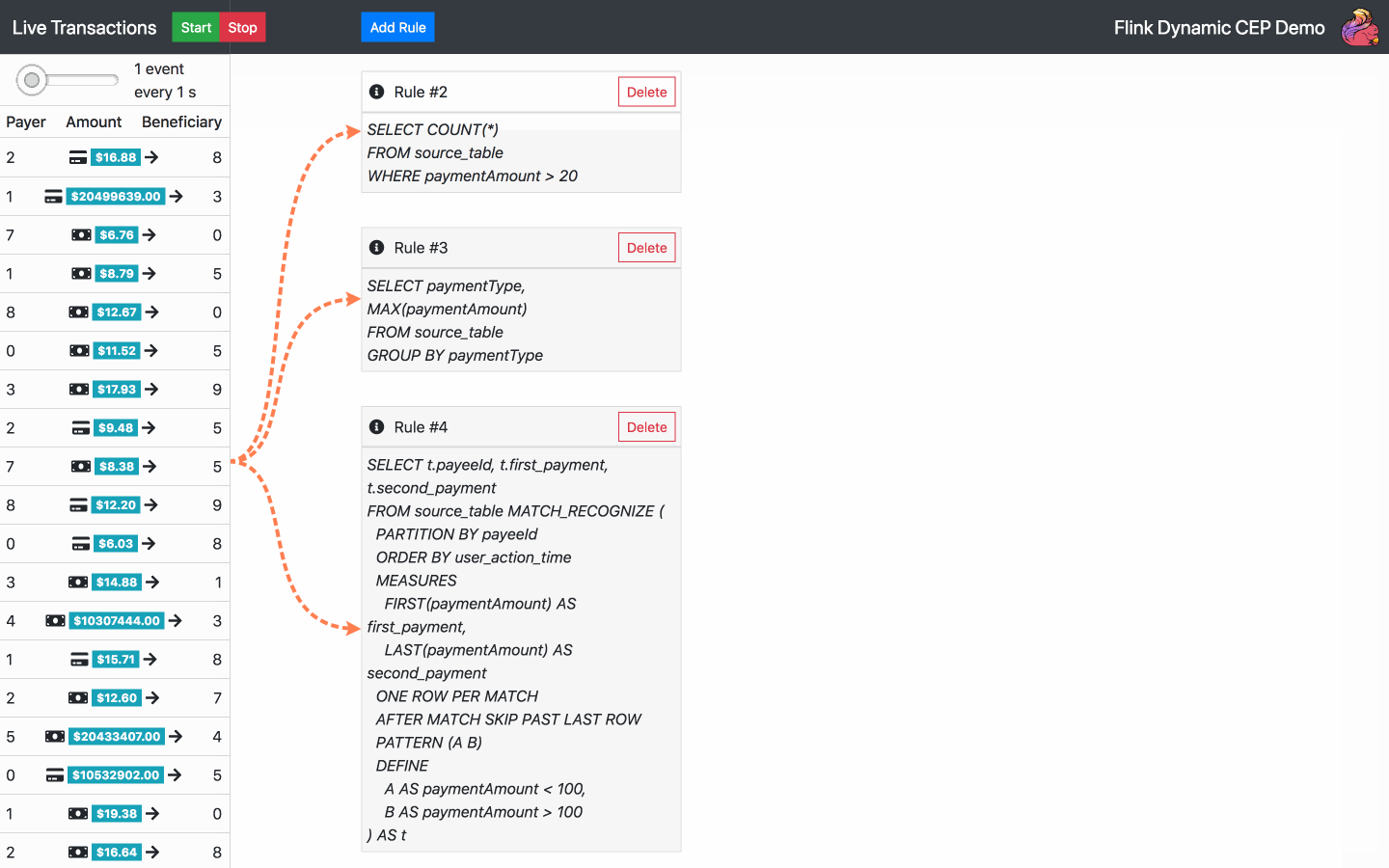
Below is the diagram of the architecture chosen for the operator

This behavior was implemented as an extension to the KeyedBroadcastProcessFunction
public class BroadcastEmbeddedFlinkFunction<KEY, IN> extends
KeyedBroadcastProcessFunction<KEY, IN, SqlEvent, Tuple4<String, Boolean, Row, Long>> {
...
public BroadcastEmbeddedFlinkFunction(
TypeInformation<IN> inTypeInfo,
List<String> expressions,
Class converterIn,
AssignerWithPeriodicWatermarks<IN> assigner)
...
}This operator requires the following information for the constructor:
inTypeInfo - type information of event source's event class (IN)expressions - a list of IN attributesconverterIn - a class of custom converter, which enables the conversion of IN to String and comma-separated String to INassigner - watermark assignerThe concept of "Flinkception" is worth noting. This is the running of a Flink mini cluster (available in the form of MiniClusterWithClientResource) inside the broadcast function. In order to execute the incoming SQL, a new MiniClusterWithClientResource for this SQL is created in each physical partition.
public void processBroadcastElement(
SqlEvent value, Context ctx, Collector<Tuple4<String, Boolean, Row, Long>> out)
throws Exception {
...
BroadcastEmbeddedFlinkCluster<IN> cluster =
new BroadcastEmbeddedFlinkCluster<IN>(
value.sqlQuery, inTypeInfo, expressions, converterIn.getClass(), assigner, startTime);
cluster.open(generateSourcePort());
clusters.put(value.sqlQuery, cluster);
...
}
public class BroadcastEmbeddedFlinkCluster<IN> implements Serializable {
...
public void open(int dsSourcePort) throws Exception {
miniClusterResource =
new MiniClusterWithClientResource(
new MiniClusterResourceConfiguration.Builder()
.setConfiguration(getConfig())
.setNumberTaskManagers(NUM_TMS)
.setNumberSlotsPerTaskManager(NUM_SLOTS_PER_TM)
.build());
miniClusterResource.before();
ClusterClient<?> clusterClient = miniClusterResource.getClusterClient();
executor = createDefaultExecutor(clusterClient);
SessionContext sessionContext = new SessionContext("default", new Environment());
sessionId = executor.openSession(sessionContext);
Runtime.getRuntime().addShutdownHook(new EmbeddedShutdownThread(sessionId, executor));
StreamExecutionEnvironment keyEnv =
(StreamExecutionEnvironment)
FieldUtils.readField(executor.getExecutionContext(sessionId), "streamExecEnv", true);
tableEnv =
(StreamTableEnvironment) executor.getExecutionContext(sessionId).getTableEnvironment();
String dsSourceHostName = "localhost";
inputSource =
keyEnv.addSource(
new CustomSocketTextStreamFunction(
dsSourceHostName, dsSourcePort, "\n", 0, customLogger),
"My Socket Stream");
clientSocket = new Socket(dsSourceHostName, dsSourcePort);
customLogger.log("Client socket port" + clientSocket.getLocalPort());
writer = new OutputStreamWriter(clientSocket.getOutputStream());
if (converterIn == null) {
BroadcastEmbeddedFlinkCluster.converterIn = (StringConverter) converterInClass.newInstance();
}
DataStream<IN> inputDS =
inputSource
.map((MapFunction<String, IN>) s -> (IN) converterIn.toValue(s))
.returns(inTypeInfo)
.assignTimestampsAndWatermarks(assigner);
Expression[] defaultExpressions = {$("user_action_time").rowtime()};
Table inputTable =
tableEnv.fromDataStream(
inputDS,
Stream.concat(
expressions.stream().map(Expressions::$), Arrays.stream(defaultExpressions))
.toArray(Expression[]::new));
tableEnv.createTemporaryView("source_table", inputTable);
resultDescriptor = executor.executeQuery(sessionId, sql);
}
...
}Communication between the “outer” Flink (where the events are acquired) and the “inner” one (mini cluster that processes the events) is done using a custom implementation of the SocketTextStreamFunction. During the mini cluster initialization, the socket is created, then each incoming event in the “outer” is converted to String in order to be written into the socket. The SocketTextStreamFunction event source is treated as a table of names source_table with column names being expressions. Using the LocalExecutor, after each event ingestion, the results of SQL query are collected by the cluster and returned by the broadcast function.
@Override
public void processElement(
IN value, ReadOnlyContext ctx, Collector<Tuple4<String, Boolean, Row, Long>> out)
throws Exception {
try {
String strValue = converterIn.toString(value);
for (BroadcastEmbeddedFlinkCluster<IN> cluster : clusters.values()) {
cluster.write(strValue);
}
for (BroadcastEmbeddedFlinkCluster<IN> cluster : clusters.values()) {
List<Tuple4<String, Boolean, Row, Long>> output = cluster.retrieveResults();
for (Tuple4<String, Boolean, Row, Long> line : output) {
out.collect(line);
}
}
} catch (Exception e) {
logger.log("processElement exception: " + e.toString());
throw e;
}
}Further work needs to be done concerning the performance and stability of the solution. Currently, for each incoming SQL rule in each physical partition, a MiniClusterWithClientResource is created, which creates a large performance overhead. A more efficient solution would be to just create one MiniClusterWithClientResource per physical partition. This architecture is shown in the diagram below. However, problems were encountered when testing such an approach. A LocalExecutor of the cluster was unable to handle the execution and processing of more than one SQL query, as only the first sent query was executed. More in-depth Flink knowledge would be needed in order to fix this issue.

Another problem that needs further work is the lost events phenomenon. During the testing of the more complicated SQL features, such as the MATCH_RECOGNIZE clause, some anticipated results were non-deterministic. This problem was hard to resolve in a limited time period, as it occurred sporadically and originated in the LocalExecutor.
A possible solution for improving both the performance and the robustness of this solution would be to replace a communication by socket in the MiniClusterWithClientResource with a Java collection-based solution. This would enable easier debugging, as the whole event path could be tracked much more easily when dealing with the collection objects as opposed to socket messaging. Moreover, such an approach would reduce the network load, which potentially cut the time and resources needed for the stream processing task.
Finally, the delivery guarantees are something to be specified, moving forward. While the at-most-once guarantees are easily achieved by the current implementation which performs one-way communication (if the internal mini cluster is killed, the messages will stop appearing), the exactly-once and at-least-once guarantees may only be achieved by creating proper two-way communication with ACK messaging.
The constructed demo showcases an interesting way of combating the recurring problem of dynamic SQL execution in Flink. This demo is a proof-of-concept, and the proposed solution has not been tested in production yet. There are still issues to be resolved, but should this be achieved, Flink will be able to perform high-volume, real-time business intelligence to its full extent.
To end, I'd like to thank Krzysztof Zarzycki and the whole GetInData team for their invaluable support - none of this would have been possible without their help :)
Last but not least, if you would like to test or know more about this proof-of-concept, do not hesitate to contact us!
—
Did you like this blog post? Check out our other blogs and sign up for our newsletter to stay up to date!
You just finished the Apache Spark-based application. You ran so many times, you just know the app works exactly as expected: it loads the input…
Read more2020 was a very tough year for everyone. It was a year full of emotions, constant adoption and transformation - both in our private and professional…
Read moreThe year 2020 was full of challenges in many areas, and in many companies and organizations. Often, it was necessary to introduce radical changes or…
Read moreKnowledge sharing is one of our main missions. We regularly speak at international conferences, we contribute to open-source technologies, organize…
Read moreThese days, Big Data and Business Intelligence platforms are one of the fastest-growing areas of computer science. Companies want to extract knowledge…
Read moreAirflow is a commonly used orchestrator that helps you schedule, run and monitor all kinds of workflows. Thanks to Python, it offers lots of freedom…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?