Tutorial
Introduction to GeoSpatial streaming with Apache Spark and Apache Sedona
We are producing more and more geospatial data these days. Many companies struggle to analyze and process such data, and a lot of this data comes…
Read moreSnowflake has officially entered the world of Data Lakehouses! What is a data lakehouse, where would such solutions be a perfect fit and how could they be introduced into the Snowflake-centered data ecosystem? We’ll walk you through this topic in our series of blog posts. Today, as an introduction to the topic, you will find the answers to questions like: Why is a data lakehouse a solution that combines all the key features of a data warehouse and a data lake, and which shortcomings of these solutions does it address? What role do open data formats (like Iceberg) play in DLH architectures and what are Snowflake Iceberg Tables? In the second part, we will share the blueprint architecture and reveal some interesting observations on how cost-efficient, flexible and secure a Data Lakehouse on Snowflake with the Iceberg format could be. Additionally we touch upon which items you have to be aware of when deciding on such a solution. Now, let’s get to the first part!
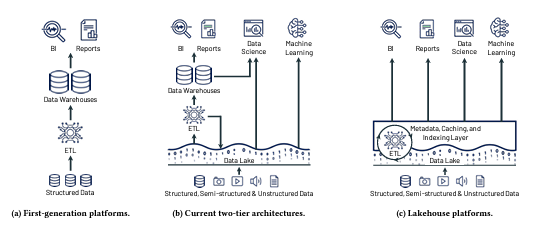
In modern data environments it’s become obvious that limiting focus on structured data and predefined schemas is no longer sufficient if you would like to get maximum value from your data assets, maximize the associated time-to-value and optimize the total cost of ownership (TCO). Traditional data warehousing is also very often connected with issues in handling massive volumes of data or varying workloads. Data Lakes on the other hand allow for the storage of raw, unstructured or semi-structured data in its native format. Although they enable flexibility in data interpretation, they may face challenges in governance and security due to a lack of predefined structures and performance optimization for structured queries. So, as often happens in nature, when none of the solutions cover all the needs, a new… third solution eventually appears.
Data Lakehouses offer a balance, supporting diverse analytics needs with the ability to handle both structured and unstructured data efficiently, in order to provide first-class support for machine learning and data science workloads. They combine the governance capabilities of data warehouses with the flexibility of data lakes, providing strong security and access controls while supporting diverse data types. Some of the most common challenges of data warehouses like data staleness, reliability, total cost of ownership, data lock-in and limited use-case support are also addressed. It looks awesome in theory, but… how is this concept introduced from a technical standpoint?
Source: Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics
In the era of Hadoop and data lakes from these days transactional consistency, schema evolution and metadata management were among the top challenges when it came to building data products. There was a need for an abstraction layer that would address these shortcomings - this is more or less how open table formats came into play. Apache Iceberg is one of the most popular ones (along with Delta Lake and Hudi) in the context of Data Lakehouse architectures.
Apache Iceberg is an open-source table format for large-scale data processing. It provides a table format that supports schema evolution, transactional consistency and efficient data pruning. The key features of Apache Iceberg from the perspective of Data Lakehouse architecture include:
Interoperability: it ensures interoperability across different data processing engines (like Spark, Trino, Flink, Hive etc) and frameworks. This allows users to leverage various analytics tools and engines while accessing the same underlying data stored in the Data Lakehouse.
Schema Evolution: allows for the evolution of table schemas over time, without requiring a rewrite of the entire dataset. This flexibility is crucial in dynamic data environments where schema changes are frequent.
Transactional Consistency: provides ACID (Atomicity, Consistency, Isolation, Durability) transactions for write operations. This ensures that data writes are either fully committed or fully rolled back, maintaining consistency.
Snapshot Isolation: supports snapshot isolation, allowing concurrent readers to operate on the same table without interfering with one another. This is important for maintaining consistent query results in multi-user environments.
Time Travel: enables querying data at different points in time, providing a historical view of the dataset. This feature is valuable for auditing, debugging and analysis of changes over time.
Metadata Management: maintains metadata on the table, including information about schema, partitions and statistics. This metadata is essential for optimizing query performance and enabling efficient pruning of data during query execution.
Optimized Query Performance: provides optimizations for query performance by enabling efficient data pruning and filtering, reducing the amount of data that needs to be scanned during query execution. This is particularly important for large-scale data lakehouse environments.
Snowflake has entered the BYOS (Bring Your Own Storage) game.
Snowflake Data Cloud supports processing big data workloads using numerous file formats, including Parquet, Avro, ORC, JSON and XML. While Snowflake’s internal, fully managed table format simplifies the storage maintenance like encryption, transactional consistency, versioning, fail-safe and time travel, some organizations with regulatory or other constraints are either not able to store all of their data in Snowflake or prefer to store data externally in open formats (like Apache Iceberg). One of the key reasons why some organizations rely on the open formats is interoperability - they can process their data safely with Spark, Trino, Flink, Presto, Hive and many more in the same tables, at the same time. Others prefer that storage costs are allocated to their cloud provider’s bill or simply prefer open formats because they don’t like to feel locked-in and like to be flexible when it comes to their architecture choices. At the end of the day it always comes down to the popular dilemma - managed vs. flexible solutions. Regardless of the reasons, fans of open table formats should be now happy as Snowflake has recently announced support for Iceberg tables.
Iceberg tables store their data and metadata files in an external cloud storage location (Amazon S3, Google Cloud Storage, or Azure Storage), which is not part of Snowflake storage and does not incur Snowflake storage costs. Such external storage might be relevant in some of the organizations due to compliance & data security restrictions. This, however, means that all management (including data security aspects) of this storage is on you (or at least not on Snowflake). Snowflake connects to your storage location using an external volume, so data is outside of the Snowflake but you keep the performance and other benefits of Snowflake (e.g., security, governance, sharing.)
Snowflake supports different catalog options - you can use Snowflake as an Iceberg catalog, but also use a catalog integration to connect Snowflake to an external Iceberg catalog such as AWS Glue, or to Iceberg metadata files in object storage. An Iceberg table that uses Snowflake as the Iceberg catalog provides full Snowflake platform support with read and write access. Snowflake handles all life-cycle maintenance, such as compaction of the table.
A general a rule of thumb is to use Snowflake Managed Iceberg when data needs to be in an open format, consumable by external processes, and where Snowflake is maintaining the table (and catalog) and Snowflake Unmanaged Iceberg when Snowflake needs to read open format Iceberg data, but is just a consumer and is referencing an external catalog (e.g. AWS Glue Data Catalog).
So it feels that with the advent of Iceberg tables, Snowflake data architectures have become more flexible and open to new types of organizations. Among the benefits, we really like the commitment to eliminating data movement, ensuring that the data stays in place, which has a positive impact on reducing latency and optimizing overall query performance.
Please note that at the time of writing, Snowflake Iceberg Tables were in Public Preview, which means there were some limitations and disclaimers for potential use. Please check the details here.
Knowing what the functionalities of Iceberg format are and its integration with Snowflake, a natural question arises - what are the most common use cases for the Iceberg format in Snowflake? Let’s consider the scenarios which we find most suitable:
As already mentioned - bigger flexibility means a greater responsibility of securing your data via IAM rules, as data is stored in your storage and can be accessed directly without going through Snowflake. Therefore, if you primarily only use your data for business intelligence, then you probably don't have the need for an open format like Iceberg. However, if you want access to your data in many different ways with different tools, then the open standard option can be more beneficial.
OK, it’s been a nice update from the field. But… is that all we have prepared? Of course, not! As a group of expert engineers we don’t just write IT novels - we like to build stuff. That was also the case with Data Lakehouse on Snowflake with the Iceberg format. In the second part of our blog post we’ll share with you our blueprint architecture and reveal a couple of interesting observations on how cost efficient, flexible and secure this kind of solution could be. Stay tuned!
Inspirations:
Snowflake Iceberg Tables — Powering open table format analytics
Apache Iceberg or Snowflake Table format? | by James Malone
Iceberg Tables on Snowflake: Design considerations and Life of an INSERT query | Medium
We are producing more and more geospatial data these days. Many companies struggle to analyze and process such data, and a lot of this data comes…
Read moreBusinesses across industries are using advanced data analytics and machine learning to revolutionize how they operate. From detecting anomalies to…
Read moreWelcome to the next installment of the "Big Data for Business" series, in which we deal with the growing popularity of Big Data solutions in various…
Read moreNowadays, companies need to deal with the processing of data collected in the organization data lake. As a result, data pipelines are becoming more…
Read moreWhat is Apache Iceberg? Apache Iceberg is an open table format for huge analytics datasets which can be used with commonly-used big data processing…
Read moreReal-time analytics are all processes of collecting, transforming, enriching, cleaning and analyzing data to provide immediate insights and actionable…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?